哈工大讯飞联合实验室发布中文RoBERTa-large预训练模型
预训练模型已成为现阶段自然语言处理领域中不可或缺的资源。近期,Facebook提出的RoBERTa模型进一步刷新了多个英文数据集的最好成绩,成为目前最流行的预训练模型之一。为了进一步提升中文自然语言处理任务效果,哈工大讯飞联合实验室、认知智能国家重点实验室发布RoBERTa-large的中文预训练模型,并且首次在CMRC 2018阅读理解挑战集上F1超过60%,预示着中文预训练模型在困难问题上首次超过“及格线”。同时,我们通过大规模实验验证该模型在多个自然语言处理任务中取得了显著性能提升。我们欢迎各位专家学者下载使用,进一步促进中文信息处理的研究发展。至此,哈工大讯飞联合实验室已发布的中文预训练模型有:
- BERT系列:BERT-wwm, BERT-wwm-ext
- XLNet系列:XLNet-base, XLNet-mid
- RoBERTa系列:RoBERTa-wwm-ext, RoBERTa-wwm-large-ext
项目地址:https://github.com/ymcui/Chinese-BERT-wwm
中文RoBERTa-wwm-large-ext模型
本次发布的中文RoBERTa-wwm-large-ext模型与先前发布的RoBERTa-wwm-ext训练模式基本一致,仅提升了模型的参数量。主要特点有:
- 预训练阶段采用wwm策略进行mask(但没有使用dynamic masking)
- 取消了Next Sentence Prediction(NSP)预训练任务
- 不再采用先使用max_len=128的数据预训练然后再用max_len=512的数据预训练的模式,取而代之的是直接使用max_len=512的数据进行预训练
- 训练步数适当延长,共计训练了1M步
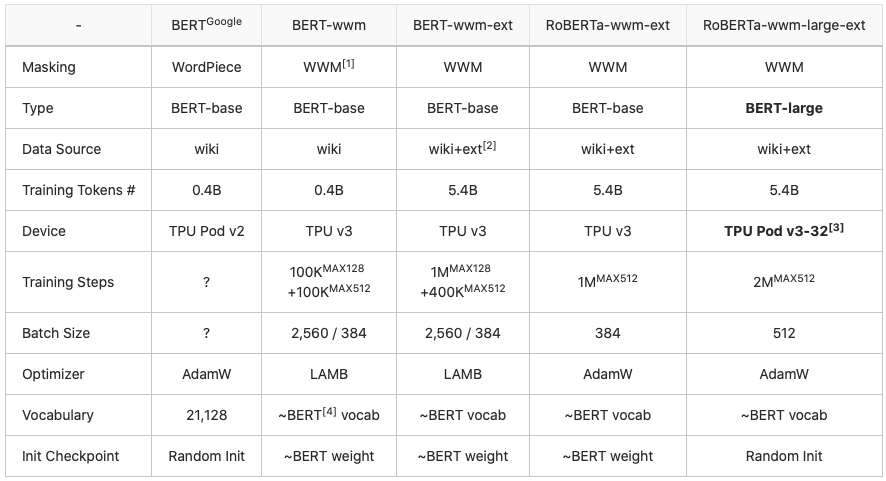
模型对比
以下是目前哈工大讯飞联合实验室已发布的部分中文预训练系列模型。前期发布的BERT模型均是BERT-base派生模型,即由12层Transformers组成,Attention Head为12个,隐层维度是768。本次发布的RoBERTa-wwm-large-ext则是BERT-large派生模型,包含24层Transformers,16个Attention Head,1024个隐层单元。
[1] WWM = Whole Word Masking
[2] ext = extended data
[3] TPU Pod v3-32 (512G HBM) 等价于4个TPU v3 (128G HBM)
[4] ~BERT表示继承谷歌原版中文BERT的属性
基线测试结果
为了保证结果的可靠性,对于同一模型,我们使用不同的随机种子训练10次,汇报模型性能的最大值和平均值。
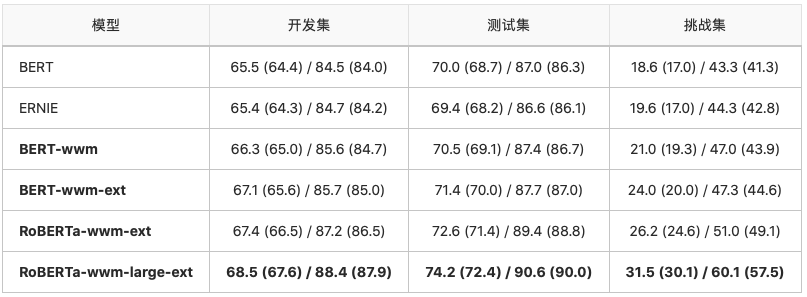
简体中文阅读理解:CMRC 2018
CMRC 2018是哈工大讯飞联合实验室发布的中文机器阅读理解数据。根据给定问题,系统需要从篇章中抽取出片段作为答案,形式与SQuAD相同。可以看到本次发布的large模型获得了显著性能提升,尤其在挑战集(包含多句推理等较为困难的问题)上的F1超过60%,说明在较难问题上该模型已基本达到“及格”水平。
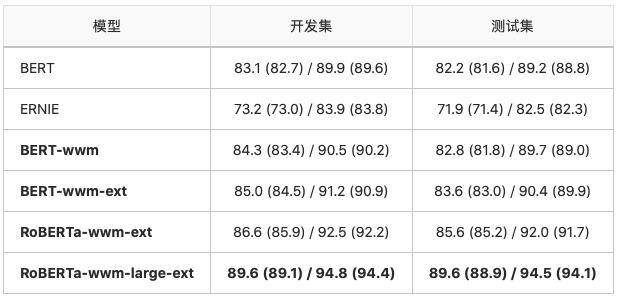
繁体中文阅读理解:DRCD
DRCD数据集由中国台湾台达研究院发布,其形式与SQuAD相同,是基于繁体中文的抽取式阅读理解数据集。
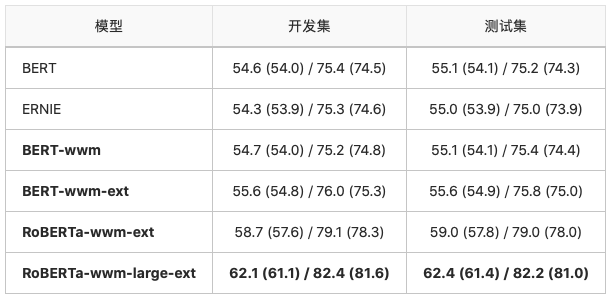
司法阅读理解:CJRC
CJRC数据集是哈工大讯飞联合实验室发布的面向司法领域的中文阅读理解数据集。需要注意的是,实验中使用的数据并非官方发布的最终数据,结果仅供参考。
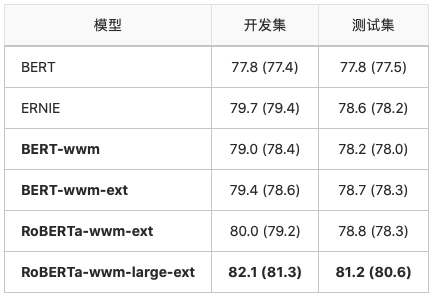
自然语言推断:XNLI
XNLI是由 Facebook和纽约大学发布的自然语言推断数据集,需要将文本分成三个类别(entailment, neutral, contradiction)中的一类。
其他数据集上的实验结果可参考GitHub项目目录。