EMNLP 2019 | 基于篇章片段抽取的中文阅读理解数据集
EMNLP 2019 | 基于篇章片段抽取的中文阅读理解数据集
本文介绍了本实验室成员在自然语言处理顶级国际会议EMNLP 2019上发表的论文。该论文提出了一种基于篇章片段抽取的中文阅读理解数据集,也是由哈工大讯飞联合实验室承办的第二届“讯飞杯”中文机器阅读理解评测(CMRC 2018)使用的数据。第二届CCL“讯飞杯”中文机器阅读理解评测研讨会(CMRC 2018)由中国中文信息学会计算语言学专委会主办,哈工大讯飞联合实验室承办,科大讯飞股份有限公司冠名,于2018年10月19日在湖南长沙圆满落幕。
基本信息
论文名称:A Span-Extraction Dataset for Chinese Machine Reading Comprehension
论文作者:崔一鸣,刘挺,车万翔,肖莉,陈致鹏,马文涛,王士进,胡国平
摘要简介
机器阅读理解(Machine Reading Comprehension, MRC)任务在近些年受到广泛关注。然而,大多数阅读理解数据集是英文材料。在本文中,我们提出了一种基于篇章片段抽取的中文阅读理解数据集CMRC 2018以丰富这项任务的语言多样性。CMRC 2018数据集包含了约20,000个在维基百科文本上人工标注的问题。同时,我们还标注了一个挑战集,其中包含了需要多句推理才能够正确解答的问题,更富有挑战性。我们给出了若干个基线系统以及在本数据集上测试验证的匿名系统。该数据集同时也是第二届“讯飞杯”中文机器阅读理解评测使用的数据。我们希望该数据集的发布能够进一步促进中文机器阅读理解的技术研究。
本文的主要贡献点:
- 我们提出了一个篇章片段抽取的中文阅读理解数据集CMRC 2018,包含两万个人工标注的问题。
- 除了常规的开发集和测试集之外,我们额外标注了一个挑战集,包含了需要综合推理才能解答的问题,对未来的阅读理解系统发起挑战。
- 所提出的数据集也可以作为跨语言研究的素材使用,来探究不同语种在同一任务上的性能表现。
CMRC 2018数据集
CMRC 2018数据集是一个基于篇章片段抽取的中文阅读理解数据集,对标英文的SQuAD数据集。系统需要阅读一篇文章,并使用篇章中的某个连续片段回答相关问题。我们下载了2018年1月22日的中文维基百科数据,并使用Wikipedia Extractor将原始数据处理为纯文本。我们也使用了opencc工具将文本中的繁体中文转为简体中文。
在篇章筛选上,我们采用了如下标准(满足任意一条则剔除):
- 包含超过30%以上的非中文文本
- 包含太多专业文本
- 包含太多特殊字符、符号等
- 采用了古文、文言文等古代汉语书写
在问题标注上,我们采用了如下标准:
- 每个篇章不超过5个问题
- 问题必须是篇章中的某个连续片段
- 鼓励问题的多样性(谁、什么时间、什么地点、为什么、如何等)
- 避免直接用原文中表述,应使用复述或句法变换来增加问题难度
- 避免答案超长(比如超过30个中文字)
除了常规的开发集和测试集之外,我们标注了一个挑战集,其中包含了需要综合推理才能解答的问题,但仍然保持篇章片段抽取的形式。挑战集采用了如下标注标准:
- 答案不能够仅靠一个句子就能推出。我们鼓励标注者提出需要多个句子综合推理才能够解答的问题。
- 如果问题的答案是一个特定的实体或日期、颜色等,该答案不能是该类型下唯一出现的。例如,如果一个人名只在篇章中出现一次,则不能够提问“谁”这种类型的问题(机器很容易挑选出唯一一个人名)。篇章中应至少出现两处及以上的同类表述以混淆系统判断。
下图给出了一个挑战集中的样例。
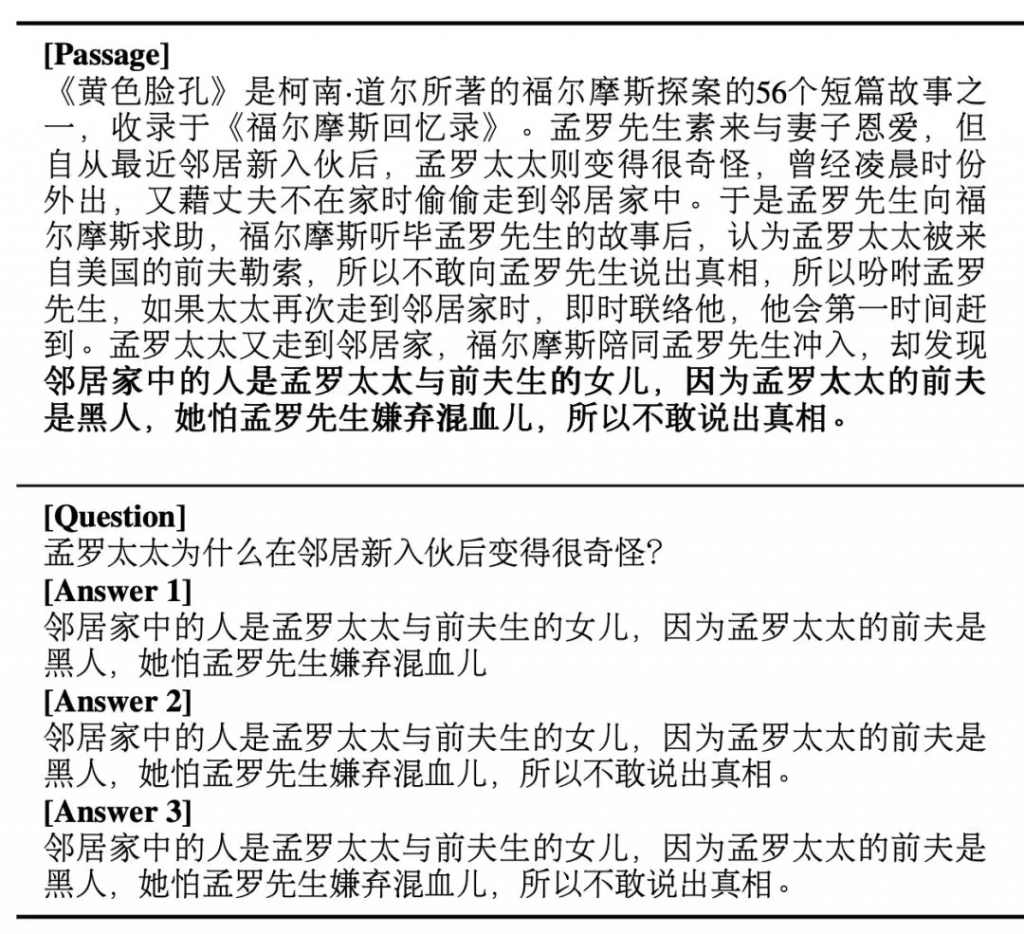
图1 CMRC 2018挑战集样例
最后我们得到了整个CMRC 2018数据集,其综合统计数据以及开发集中的问题分布如下所示。
表1 CMRC 2018数据集的统计信息
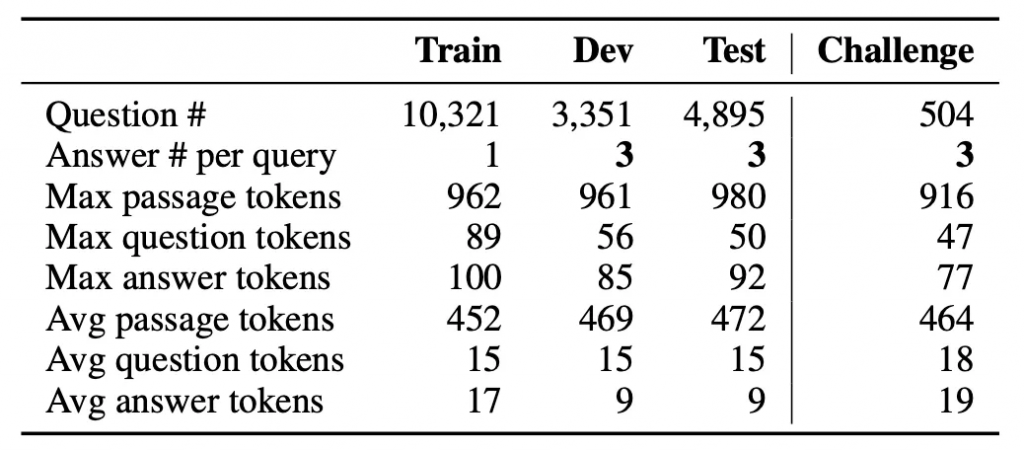
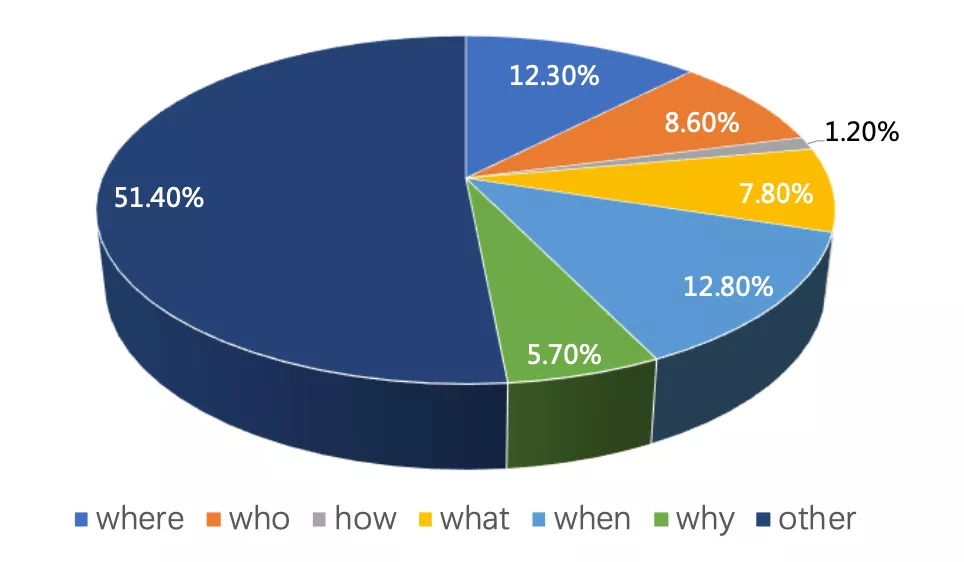
图2 CMRC 2018开发集上的问题类型分布
基线系统
我们提供了基于中文BERT、多语种BERT的基线系统来测试该数据集的难度。评价标准采用了EM(精准准确率)以及F1(模糊准确率)。同时,我们提供了预估的人类平均水平供未来参考。
表2 CMRC 2018数据集上的效果
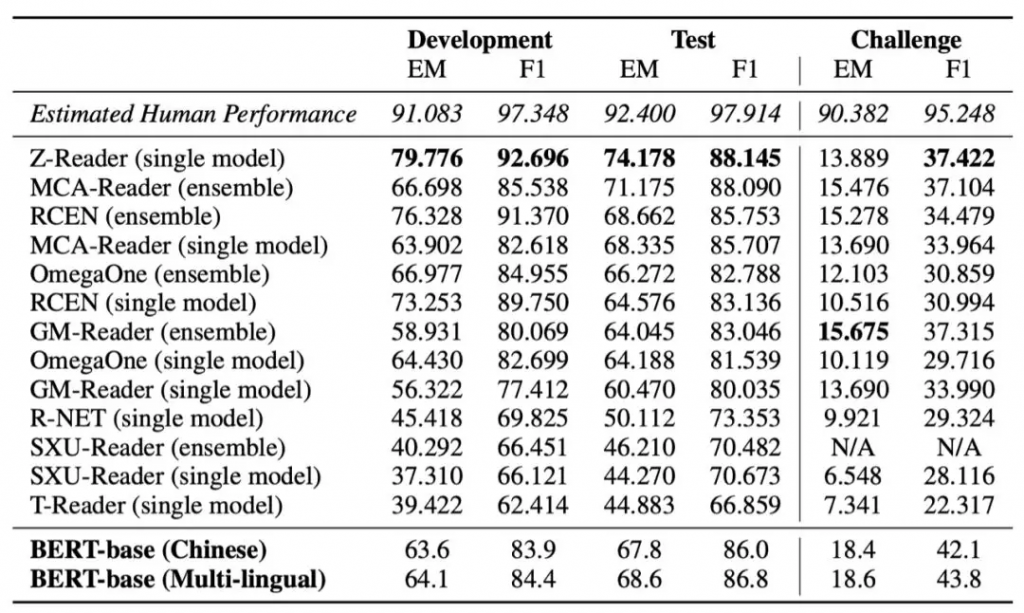
我们可以看到多数系统在开发集和测试集上取得了不错的效果。相比于英文SQuAD数据上已有部分系统超过人类平均水平,在CMRC 2018数据集上暂未有系统超过人类平均水平,说明该数据集具有一定的难度。同时我们可以看到在挑战集上,多数系统的效果距离人类平均水平还有非常大的差距,说明目前的模型在需要复杂推理和综合归纳的问题上仍然具有较大的提升空间。
开放式挑战
为了进一步促进中文机器阅读理解技术发展,评测委员会决定开展CMRC 2018 Open Challenge,继续接收评测系统在隐藏的测试集和挑战集上进行评测,同时将结果更新至Open Challenge排行榜中。该挑战赛将作为一个持续的项目进行运营,期待各参赛单位所研发的系统能够进一步提升挑战集合的技术水平。
结论
在本文中我们提出了一个基于篇章片段抽取的中文阅读理解数据集CMRC 2018,包含了两万个人工标注的问题。同时该数据集还包含一个挑战集,包含了需要综合推理才能够解答的问题。虽然多数系统在开发集和测试集上能够达到较好的水平,但仍未超过人类平均水平,而挑战集上的结果更是距离人类平均水平较远。我们希望该数据集的发布能够进一步促进中文机器阅读理解技术的发展,并且欢迎更多的研究者在我们的挑战集上测试系统效果。
延伸阅读
原文:崔一鸣
编辑:HFL 编辑部
