实验室荣登多步推理阅读理解评测HotpotQA榜首
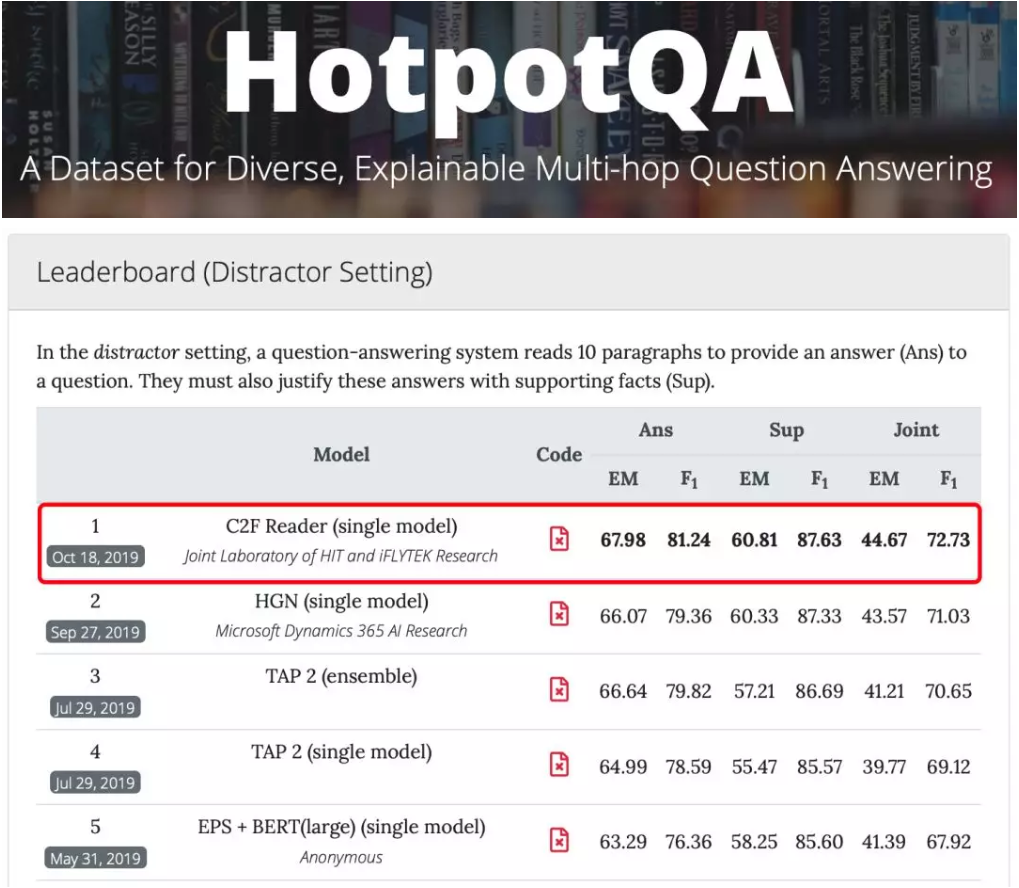
2019年10月18日, 认知智能国家重点实验室、哈工大讯飞联合实验室(Joint Laboratory of HIT and iFLYTEK Research, HFL)与河北省讯飞人工智能研究院与联合团队在由卡内基梅隆大学(CMU)、斯坦福大学和蒙特利尔大学联合发起的多步推理阅读理解评测HotpotQA中荣登榜首,全面刷新所有评测指标,其中综合模糊准确率(Joint F1)指标达到72.73。
自2018年发布以来,多步推理阅读理解评测HotpotQA吸引了大量高校和研究机构参与,其中包括微软、IBM研究院、上海交通大学、日本电报电话公司(NTT)、华盛顿大学等。
传统的阅读理解只需要模型在单篇文章中阅读,进而回答出某个特定段落的答案。而HotpotQA,不仅将模型需要阅读和理解的文本范围由一篇扩展到了多篇,还要求能对多个篇章中的逻辑关系构建两步及以上的推理链。
HotpotQA评测根据提供的篇章数量分为两个赛道:
- 干扰项赛道(Distractor Setting):每个问题提供10个备选篇章
- 全维基赛道(Fullwiki Setting):每个问题的备选篇章范围扩展到整个维基百科
本次比赛,讯飞参加的是干扰项赛道(Distractor Setting)。该赛道更侧重于考察模型的文本推理能力,同时也是参赛队伍最多的赛道。
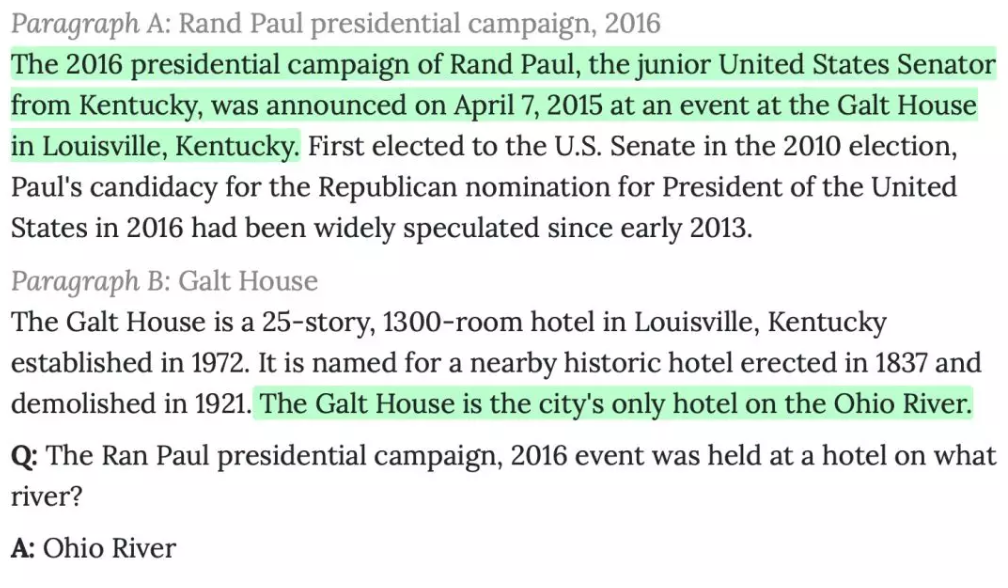
下图中给出了一个HotpotQA数据的示例,向机器询问“Rand Paul在2016年宣布竞选总统活动所在的酒店位于哪条河上?”。为了回答这个问题,机器需要首先从备选篇章中寻找到与问题相关的篇章。得到这些篇章后,我们从第一个篇章中得知该活动位于Galt House这家酒店。在阅读另一个篇章时,机器得知该Galt House这家酒店位于Ohio River上。最终,机器从这两条佐证证据(文章中绿色部分)推理得到答案“Ohio River”。
其次,为了证明模型确实利用了原文中的相关证据进行推理并提升模型的可解释性,HotpotQA不仅要求模型给出最终答案,还要求模型给出推理所用到的佐证证据(Supporting Facts)。在评价指标上,HotpotQA评测会根据答案和佐证证据的精确匹配率(EM)和模糊匹配率(F1)求得最终的联合精确匹配率和模糊匹配率(Joint EM / F1)。从最终评测结果可以看出C2F Reader模型的得分显著高于榜单其他公开以及非公开的技术方案。
本次提交的C2F Reader(Coarse-to-Fine Reader)模型在结合了目前主流的基于预训练的语义表征模型BERT的基础上,针对需要多步推理的阅读理解任务进行了优化设计,主要包括以下三个特点:
- 模型采用了由粗到细的架构(Coarse-to-Fine)设计。模型先通读多个篇章,寻找并挑选与问题最相关的内容进行精读,从而得到更为准确的答案。
- 采用多任务学习(Multi-Task Learning)的方式,在逐步求精的计算过程中输出支持证据。最后基于所选择的支持证据寻找得到答案,使模型在提升准确率的同时拥有一定的可解释性。
- 使用了预训练模型来进一步丰富文本的语义表示,同时应用了图神经网络(Graph Neural Network,GNN)模型来模拟人类在进行文本推理过程中从一个实体跳转到另一个实体的推理过程。
目前,人工智能正经历由感知智能向认知智能迈进的关键时期,为机器在理解文本语义的基础上进一步赋予推理能力对认知智能的研究和发展具有重大的意义。