实验室联合组织国际语义评测任务SemEval 2021——Task 4

国际语义评测大会SemEval(International Workshop on Semantic Evaluation)是全球范围内影响力最强、规模最大、参赛人数最多的语义评测竞赛。 国际语义评测大会SemEval-2021现已发布trail data, 并将在10月1号发布训练数据。今年SemEval-2021 大会,认知智能国家重点实验室和加拿大Queen’s University、中国科学技术大学的研究团队联合组织了Task-4: Reading Comprehension of Abstract Meaning评测任务。
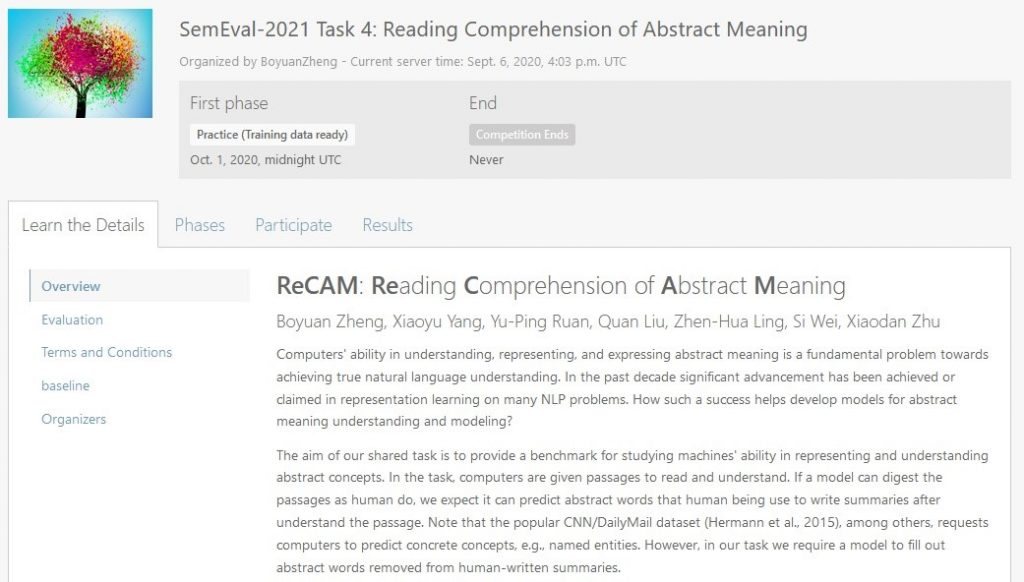
Task4: Reading Comprehension of Abstract Meaning (针对抽象概念的阅读理解)
评测任务链接:https://competitions.codalab.org/competitions/26153
理解抽象概念是人类的重要智能之一,同时也是真正做到自然语言理解的重要突破。本任务是探索当前最新的NLP技术在阅读理解抽象概念上的能力。
当前阅读理解侧重要求计算机回填实体概念(如命名实体),与之不同的是本任务则专注计算机阅读理解抽象概念的理解能力。该任务分为三个子任务。
• Subtask-1: ReCAM: Imperceptibility
相对于apple和donut这样相对具体的概念,计算机能否理解culture和economy这样的抽象概念?抽象概念的一个定义是Imperceptibility(Spreen and Schulz, 1966)。该子任务的目标是探索计算机对这类抽象概念的能力。
• Subtask-2: ReCAM: Nonspecificity
第二个任务关注另一种抽象概念: Nonspecificity (Changizi, 2008). 比如计算机阅读了一篇关于apple和banana的文章,应当有能力抽象出这是一篇关于fruit的文章。这样的抽象能力对于summarization等应用都很重要,然而当前最好的NLP技术到底做得怎么样呢?
• Subtask3: ReCAM-Intersection
在第三个任务则是想要探究上述两种抽象之间的关联。具体目标是探索在Subtask-1和Subtask-2两个任务中,如果在一个任务上有很好的性能模型,是否也能在另一个任务上同样有很好的性能?
在SemEval中出现了很多有影响力的任务和高质量的数据集, 例如IBM参与的Sentiment Analysis in Twitter,Amazon Research参与的OffenEval,Stanford 参与举办的TempEval。很多数据集都成为了领域内Benchmark。
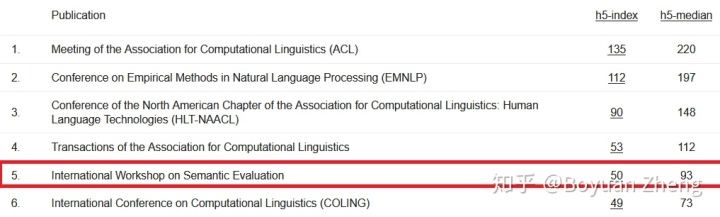
根据Google Scholar的数据,发表在SemEval的文章在Computational Linguistics领域的影响力仅次ACL/EMNLP/NAACL三大会议和最大的期刊TACL,并位于NLP会议、期刊中的第五位。
SemEval-2021的赛事组织者都是全球NLP领域中很有影响力的学者,比如Aurelie Herbelot(University of Trento), Xiaodan Zhu(Queen’s University), Nathan Schneider(Georgetown University) 和 Alexis Palmer(University of North Texas)。
每个参赛者在完成某个task之后,可以撰写一篇论文描述自己的方法和结果并投稿到SemEval-2021上。SemEval-2021将于2021年夏季,与NLP三大顶会之一共同召开。论文被接收的参赛者可以参与会议,与全球的学者一同交流探讨。
参赛者可以选择感兴趣的赛道参加竞赛,并可以通过SemEval的官网来搜索感兴趣的研究任务,了解详情并报名参加。