第六届中文语法错误诊断大赛CGED中夺冠
近日,第六届中文语法错误诊断大赛(CGED)研讨会于AACL 2020大会“面向教育技术的自然语言处理(NLPTEA)”workshop中顺利举行。今年共有国内外14支队伍参赛,提交了44个系统。讯飞、阿里、上交、南大、有道、外研社、新华社等团队均有精彩表现。其中,哈工大讯飞联合实验室团队获得综合排名第一的成绩,多项核心指标保持领先。
在语病识别、语病分类、语病定位、语病修正四类核心指标中,实验室在两项关键指标中获取冠军,另外获得一项第二和一项第三。这也是继上一届大赛(CGED 2018)夺冠后,持续保持技术领先的又一份成绩单。
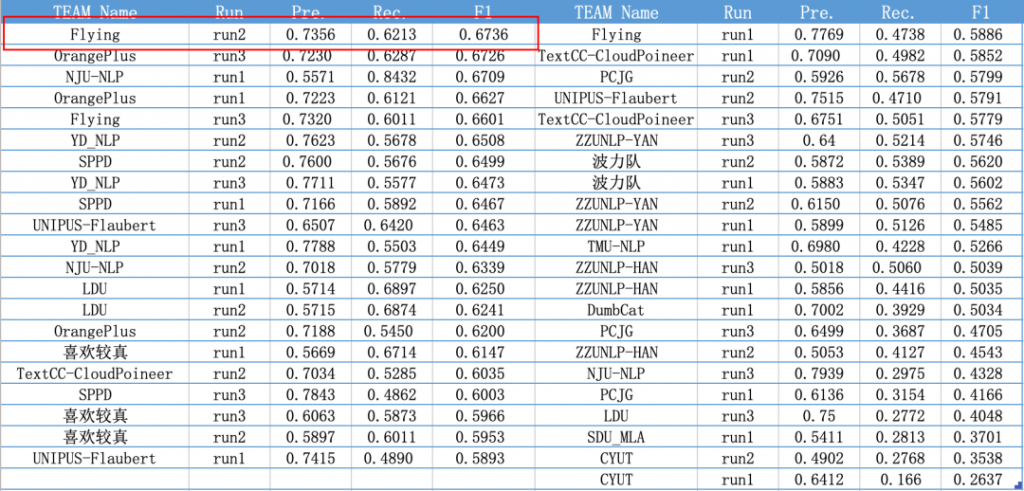
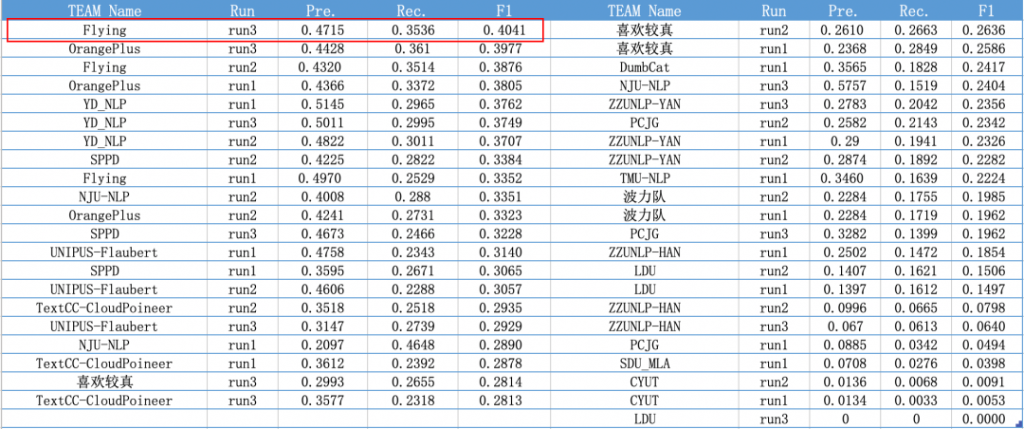
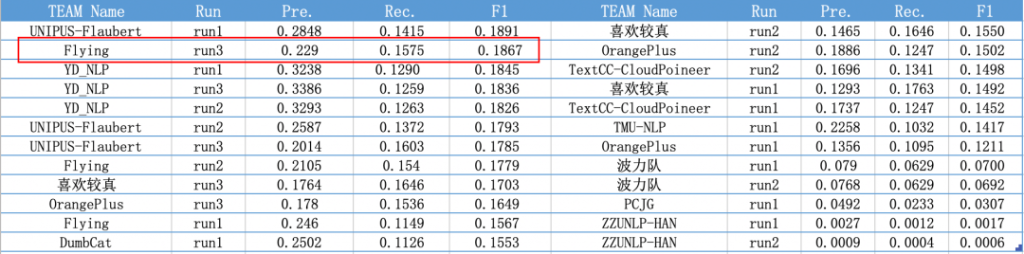
本次参赛评测方案,主要分为检测和修正两部分。在检测任务中,我们提出了ResBERT检测模型,这种模型可以帮助我们更好地检测出语法的错误类型与位置信息等。
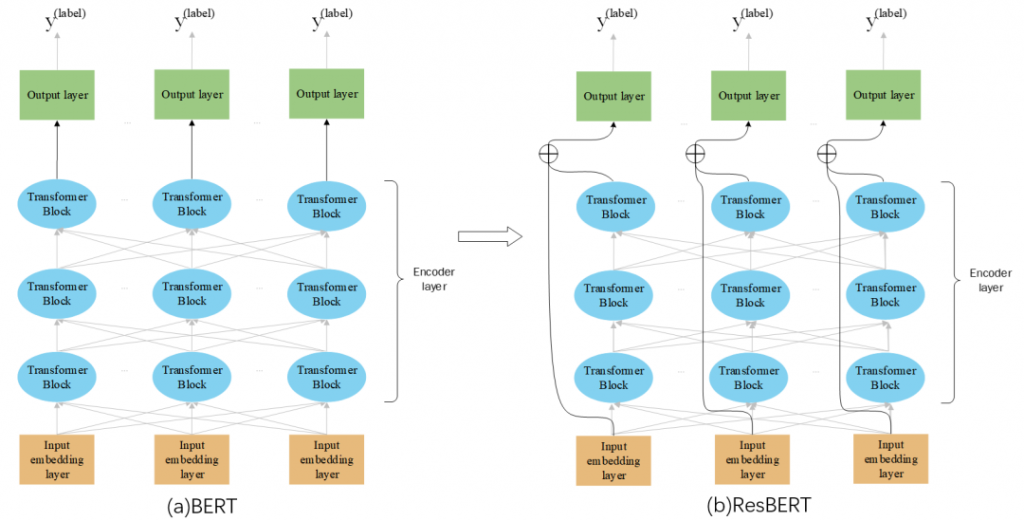
在修正任务中,我们针对缺失和用词不当错误分别采用如下两种方案进行修正:针对缺失错误,我们首先预测缺失位置、缺失字数,然后再使用语言模型生成候选修正结果,最后通过对多个候选修正结果的综合比较来确定最终修正结果。针对用词不当错误,我们综合考虑字音、字形相似度以及语言模型打分来选出最终的修正结果。
当然,我们看到今年的比赛中语病修正的指标还很低,最高的F1值也未超过0.2,原因是什么呢?我们分析评测数据来看,数据以单句形式给出,比如“那个时候我尝尝去美术馆参观画。”语病修正的参考答案为:将“尝尝”改为“尝试”,而合理的修正方法其实有很多种,比如也可以改成“常常”等。仅通过单句的信息,无法确定唯一的修正结果,需要更多的上下文信息才能确定作者所要表达的真实意图。这给评测数据的构建也提出了不小的挑战。
因此,要想提升语病修正的效果并在实际产品中应用,对于篇章级文本的诊断分析是非常有必要的,这也给未来的评测和技术提出了更高的要求。