CoNLL 2019 | TripleNet对话回复选择模型
CoNLL 2019 | TripleNet对话回复选择模型
本文介绍了本实验室在自然语言处理重要国际会议CoNLL 2019上发表的论文。论文提出了一种检索式人机对话中多轮回复选择的新架构TripleNet。
基本信息
论文名称:TripleNet: Triple Attention Network for Multi-Turn Response Selection in Retrieval-based Chatbots
论文作者:马文涛,崔一鸣,邵楠,何苏,张伟男,刘挺,王士进,胡国平
摘要简介
检索式对话是业界人机对话系统的主流架构,虽然近年来取得了诸多进展,但在回复质量上存在明显问题。我们发现其中一个重要原因是对当前问题Query的挖掘不够,目前的工作基本都是通过建模<Context, Response>的关系来选择回复Response,这导致现有的模型倾向于选择与上下文Context中某一句相似度很高却与当前Query缺少相关性的回复。受到机器阅读理解相关工作的启发,我们发现对话上下文中不同对话的重要性通常也是由当前Query来决定的。因此,我们提出了基于<Context, Query, Response>三元计算的新架构TripleNet,其核心模块Triple Attention可以同时对称地计算<C, Q ,R>三者之间的关系,从而将Query的信息显式建模进来。我们在大规模的英文数据集Ubuntu和中文数据集Douban上分别验证并发现该模型可以显著提升回复选择的质量,并取得了目前state-of-the-art效果,为检索式人机对话系统提供了一种新的模型架构。
动机
多轮对话的回复选择(Multi-turn Response Selection)是目前检索式对话系统面临的主要挑战之一,相关技术的研究对工业界的人机对话系统具有显著的推动作用。近年来的一些工作发现,对于对话上下文中不同的粒度信息(如词、句子、上下文等)的建模对提升回复选择质量非常重要。然而目前的对话模型还是很容易出现“语义漂移”现象,也就是所选择的回复跟上下文中某一次对话相关而跟当前Query并不相关。其中一个重要原因就是目前的对话模型平行地建模上下文中的每一次对话,包含当前Query。
我们发现,同机器阅读理解任务类似,在多轮对话的回复选择中,上下文中不同对话的重要性也是当前Query决定的。即便是当前Query缺乏内容,也是一种将对话的焦点转移的信息。因此,我们提出一种基于对话上下文、当前Query和候选回复三元计算的新架构TripleNet,并使用一种新的注意力机制Triple Attention对称地建模<C, Q, R>三者之间的关系。本文的主要贡献如下:
- 提出了一种新的三元注意力计算机制Triple Attention,能够同时建模多轮对话回复选择任务中的<C, Q, R>,而不仅仅是之前工作中的<C,R>;
- 我们使用了一种层次的表示模块,可以从Char到Context四个层次上更加全面地建模对话中不同层级的信息;
- 我们在英文和中文的两个大规模对话语料Ubuntu和Douban上的测试结果显著超过了已有模型,取得了state-of-the-art效果。
模型
3.1 任务定义
与之前的工作有所不同,本文将多轮对话的回复选择任务定义为:给定对话上下文C、当前问题Q和候选回复R,构建一个模型预测回复为正确回复的概率,即p=g(C, Q, R),当前问题Q仍然作为C的最后一次对话,而C除上下文级别信息外还包含三个层次的信息:
- 上下文中的多次对话Utterance,即:
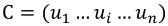 ;
; - 每次对话U包含多个单词Word, 即:
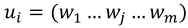 ;
; - 每个词Word包含多个字符Char,即:
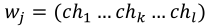 ;
;
其中n, m, l分别是Context, Utterance和Word的最大长度。
3.2 模型概览
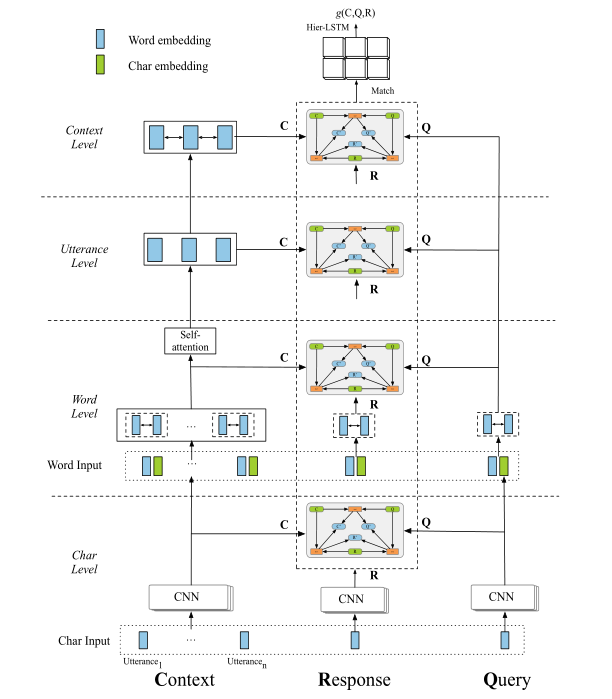
输入:<Context, Query, Response>
输出:当前候选回复Response为正确回复的概率p主要模块:层次表示(Hierarchical Representation)、三元注意力(Triple Attention)、三元匹配(Triple Matching)和预测模块
3.3 模型细节
3.3.1 层次表示
字符级别(Char-level): 我们使用CNN和Max-Pooling构建字符级别表示:
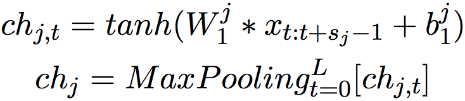
词级别(Word-level): 由预训练的词向量、上述字符级别输出的表示和词匹配特征共同构成,我们使用一个共享的双向LSTM得到带上下文信息的词级别表示:
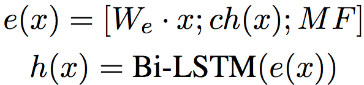
对话级别(Utterance-level): 给定第K个对话的表示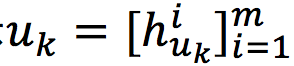 ,我们使用Self-Attention来构建Utterance-Level的表示:
,我们使用Self-Attention来构建Utterance-Level的表示:
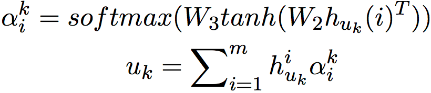
上下文级别(Context-level): 我们将对话级别的表示输入另外一个双向的LSTM从而建模不同对话之间的信息:
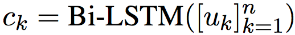
3.3.2 三元注意力
为了同时建模对话上下文、当前Query和候选回复三者之间的联系,我们设计了一种新的注意力计算机制Triple Attention。由于<C,Q,R>三者之间内容上的对称性,Triple Attention在计算上也是完全对称的,其结构如下图所示:
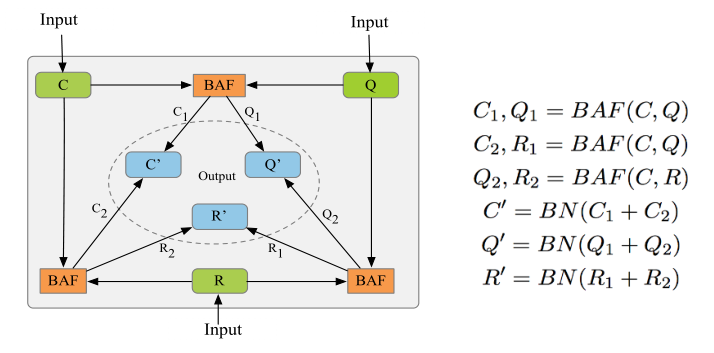
对于三元组中的任意一个组合对,我们将其输入到函数Bidirectional Attention Function(BAF)进行双向Attention计算。给定任意两个序列P和Q,该函数的计算如下图:
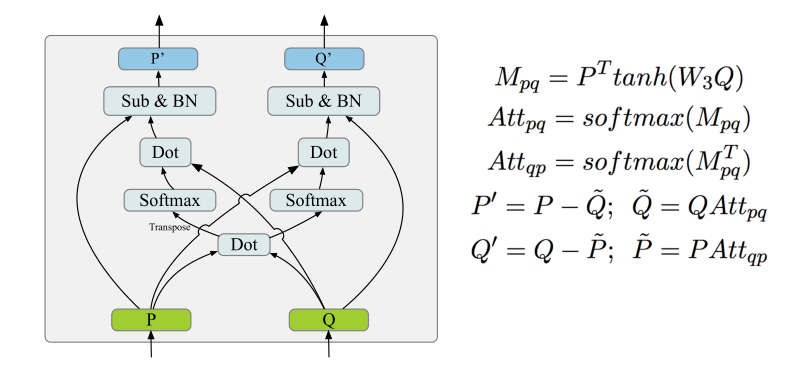
在Triple Attention计算中,对于三元组中的每一个元素,都会同时与另外二者进行BAF的双向Attention计算得到两个新的表示,然后将二者融合归一化(Batch Normalization)后得到其最终的表示。我们可以发现,每一个元素表示的更新都会同时依赖另外二者的信息,从而综合考虑<C, Q, R>三者之间的联系。
3.3.3 三元匹配与预测
三元匹配(Triple Matching):我们以候选回复R为中心分别进行R-C,R-Q之间的匹配计算,以Char-level的计算为例:
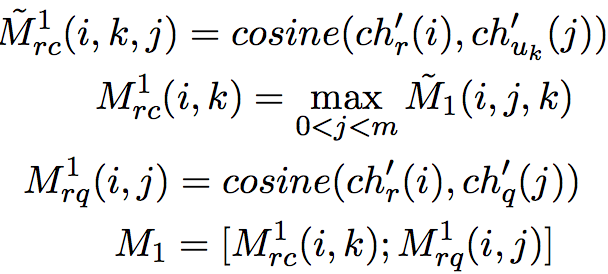
注意对于上下文来说,字符和词级别的表示都是以词为粒度,而对话和上下文级别的表示是以对话为粒度的,所以字符和词级别的匹配结果会多出一个维度,因此这里使用了一个池化层进行降维。
融合和预测(Fusion and Prediction):我们将四个层次的匹配结果拼接之后,使用层次的LSTM和Max-Pooling进行降维,然后使用激活函数sigmoid做最终的预测:
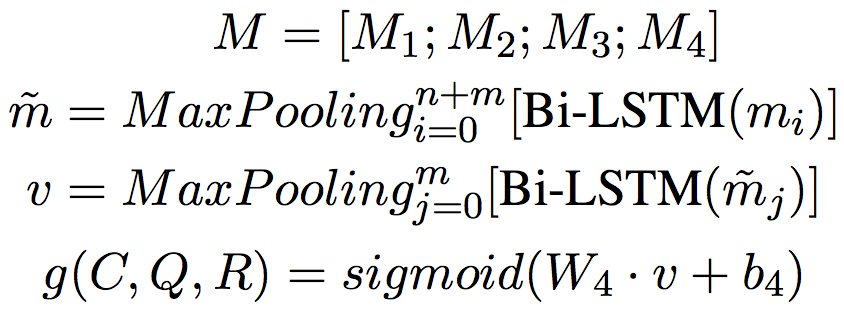
实验
4.1 数据集
我们首先在大规模的Ubuntu对话数据集上进行了实验,评估指标上我们延续之前的工作中使用K位置的召回率R_n@k。为了验证模型效果的迁移性,我们进一步在中文的豆瓣数据集上验证了效果,评估指标上增加了MAP(Mean Average Precision)、MRR(Mean Reciprocal Rank)和P@1,数据集详细信息请见论文4.1部分。
4.2 实验结果
整体实验结果如下图:
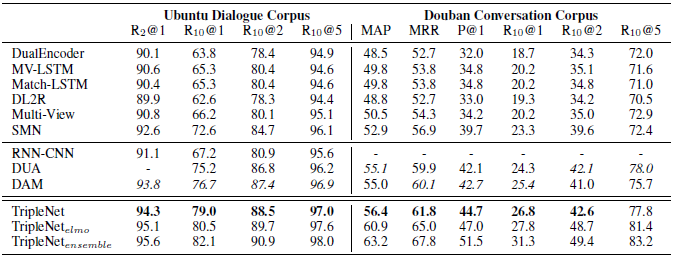
我们在两个数据集的所有指标上都显著超出了目前的state-of-the-art模型DAM,为了进一步提升效果,我们使用了预训练的语言模型ELMo,并在其基础上使用6个不同模型进行了模型融合,最终在Ubuntu数据集上达到了接近人类水平的效果,其中人类水平在R_10@1是83.8(lowe et al., 2016)。
4.3 消融实验
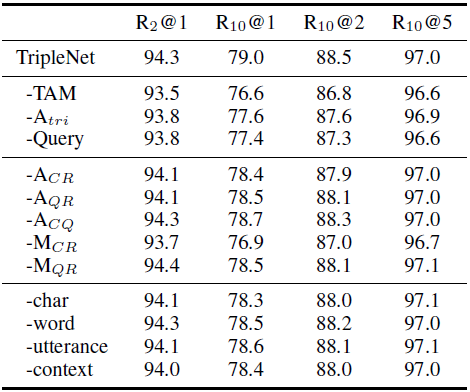
为了探究模型各个部分的效果,我们基于Ubuntu数据集进行了消融实验。首先,我们将模型各个主要模块拆除,包括三元注意力及匹配计算(-TAM)、三元注意力(-A_tri)和Query部分(-Query)。因为我们在Context中依然保留Query作为最后一次对话,所以我们去掉Query部分后并不影响对话信息的完整性。我们发现这三部分都会导致模型效果显著下降,证明了Triple Attention及Query单独建模的有效性。另外,我们对各模块进行了细分的消融实验,我们意外发现Char-level的计算在各个层次中最为重要。
讨论
在上述实验中,我们发现Query的显式建模效果提升明显。那么在整个对话上下文中,各轮对话对于回复的选择分别有多大影响呢?为了进一步探究这个问题,我们使用消融实验中TripleNet(-Query)模型(为了保证模型对各轮对话处理相同),基于Ubuntu数据集依次在训练和测试两个过程中同时去掉各轮对话内容,然后统计每次实验效果的降幅:
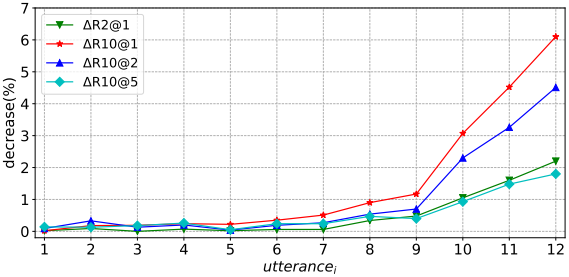
其中Query为Context中最后一次对话即Utterance_12, 从实验中我们发现:
- 去掉Query会导致最为显著的效果下降(R_10@1下降超过6个点),说明Query在整个上下文中尤为重要;
- 最后3轮对话都会带来效果的明显下降,而超过4轮以上降幅趋于稳定,说明最后3到4轮对话对回复的影响更为直接。
综上,我们发现对话上下文中不同对话的重要性具有明显的统计规律,在之后的工作中我们应该将更多的注意力放在最后几轮对话上。
结论
本文主要提出了一种基于Triple Attention的面向多轮对话回复选择任务的新架构TripleNet,通过一个对称的Attention计算方式将Query的信息显式地建模进来。与之前工作最大的不同在于,我们同时建模<C, Q, R>三者之间的内部联系,而不仅仅是<C, R>两者之间的关系。TripleNet在大规模的中英文两个对话数据集上均取得了显著的效果提升,并且通过消融实验我们证明了这种三元注意力计算的有效性。本文的核心在于提出这种三序列的对称注意力计算方式Triple Attention,在之后的工作中我们会尝试将这种注意力计算迁移到其他NLP任务如问答、阅读理解等任务中,从而进一步测试其泛化能力。
延伸阅读
- EMNLP 2019 | 法小飞:中文法律智能助手
- EMNLP 2019 | 基于篇章片段抽取的中文阅读理解数据集
- EMNLP 2019 | 跨语言机器阅读理解
- 哈工大讯飞联合实验室三篇论文被EMNLP-IJCNLP 2019录用
