CCL 2019 | 中文法律阅读理解数据集CJRC
本文介绍了哈工大讯飞联合实验室(HFL)发表在国内重要自然语言处理会议CCL 2019上的一篇论文,提出了一种基于篇章片段抽取的中文法律阅读理解数据集CJRC。该数据集也是SMP2019“中国法研杯”中文法律阅读理解比赛中所使用的数据集,该比赛由中国中文信息学会社会媒体处理专委会(CIPS-SMP)、中国司法大数据研究院主办,科大讯飞股份有限公司、哈尔滨工业大学联合承办。2019年8月17日,SMP 2019(第八届全国社会媒体处理大会,The Eighth China National Conference on Social Media Processing)法律阅读理解技术评测研讨会在深圳圆满落幕。
基本信息
论文名称:CJRC: A Reliable Human-Annotated Benchmark Dataset for Chinese Judicial Reading Comprehension论文作者:段兴义,王宝鑫,王梓玥,马文涛,崔一鸣,伍大勇,王士进,刘挺,霍天翔,胡振,王珩,刘知远
摘要简介
本文提出了首个中文法律阅读理解数据集,该数据集包含约10,000篇文档,主要涉及民事一审判决书和刑事一审判决书,数据来源于中国裁判文书网。通过抽取裁判文书的事实描述内容(“经审理查明”或者“原告诉称”部分),针对事实描述内容标注问题,最终形成约50,000个问答对。该数据集涉及多种问题类型,包括片段抽取型问题(Span-Extraction)、是否类问题(YES/NO)、拒答类问题(Unanswerable),期望可以覆盖真实场景中大多数类型的问题。我们希望通过该数据集,可以进一步促进法律领域相关任务的技术研究,例如要素抽取、问答系统、推荐系统等。以要素抽取为例,传统的要素抽取需要预定义大量标签,而由于裁判文书种类以及涉及案由(罪名)的多样性,使得标签定义工作比较繁重,通过阅读理解技术能够一定程度上避免这个问题。
本文的主要贡献有如下几点:
- 本文提出首个中文法律阅读理解数据集,填补了法律领域阅读理解研究的空白;
- 本文提出的数据集涉及范围较广,包含约188种民事案由,138种刑事罪名;涉及问题种类较多,包括片段型、是否类以及拒答类问题;应用前景较广阔,比如要素抽取、信息检索、问答系统等;
- 通过基线系统、参赛系统与人类指标的对比,说明在该数据集上仍存在较大的提升空间。
数据集介绍
CJRC数据来源于中国裁判文书网,抽取裁判文书的“经审理查明”或“原告诉称”作为事实描述内容,长度不少于150个字。在试标注某几种案由的过程中发现,所能提出的问题种类较少。同时,在经过标注人员的偏向性标注后(即习惯提问常见问题,比如时间、地点等)所提的问题种类会更少,数据集难度较低。为此,最终选择了188种民事案由和138种刑事罪名,数据分布如图1:
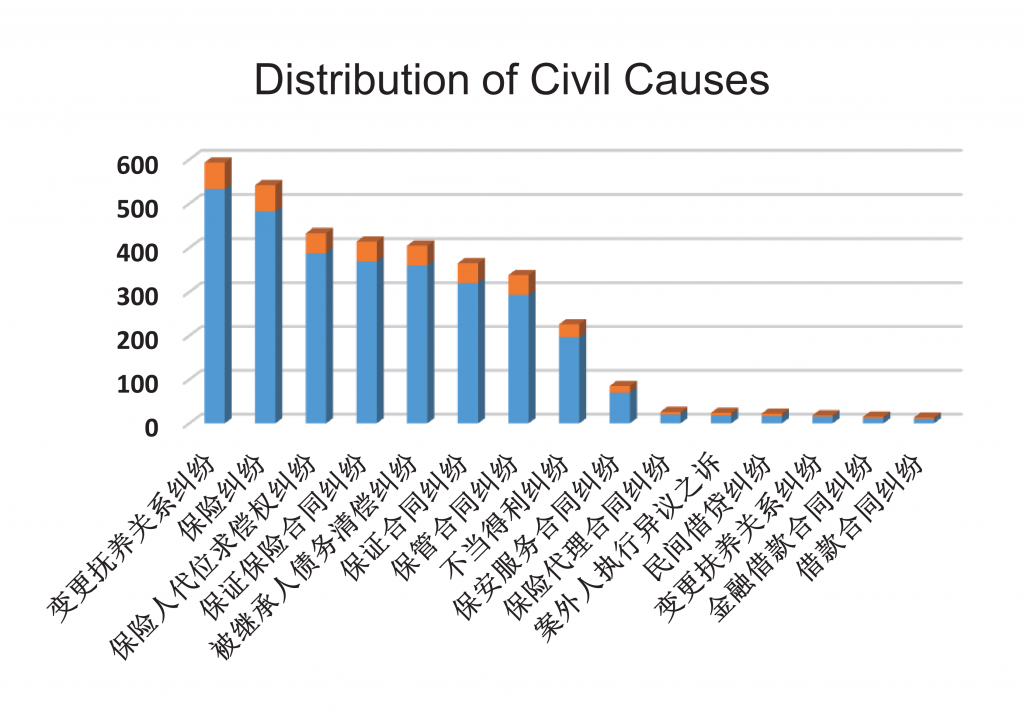
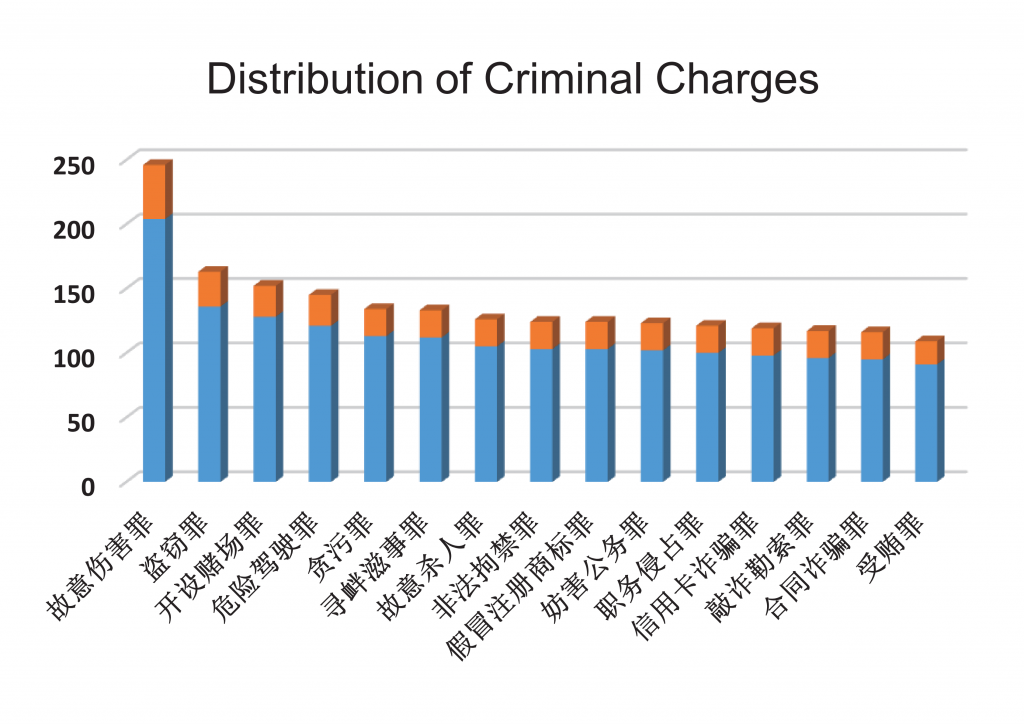
图1 民事案由和刑事罪名的数据分布
我们搭建了数据标注平台进行数据标注,标注规范如下:
- 答案应选择可行答案中最短的情况;
- 增大是否类以及拒答类问题比例;
- 避免使用原文内容进行提问,应尽量用自己的话转述;
- 尽量保证问题的多样性。
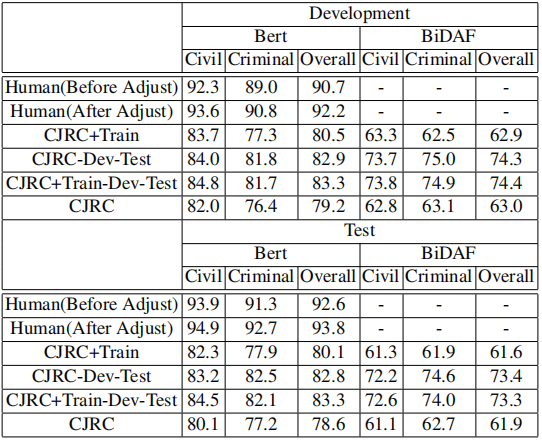
我们参照CoQA数据集In-Domain和Out-of-Domain的设置,根据案由(罪名)划分In-Domain和Out-of-Domain,并进行实验分析,结果显示这种领域内外的划分效果不太明显,甚至表现出领域外测试集比领域内测试集指标高的现象(如表1)。可能原因有两点:一是某些案由是类似的,比如房屋买卖合同纠纷和房屋租赁合同纠纷,可能都涉及房屋中介、房屋质量等问题;二是时间、地点等类型的问题更常见。最终我们放弃领域内外的设定,转而只考虑民事和刑事两种数据类型,因为民事更偏向要素类问题,刑事更偏向描述类问题,两者存在较大差异。
表1 In-Domain和Out-of-Domain的实验设置效果对比
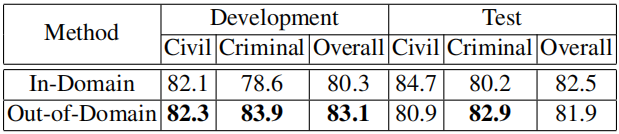
通过初步实验分析,基线系统(BERT)与人类差距较小(9.8%),为了进一步增加数据集难度,我们分析了片段抽取型问题、是否类问题以及拒答类问题的难易程度,发现拒答类问题难度最大,所以增加开发集和测试集中拒答类问题的比例,经过数据分布的调整,基线系统与人类的差距增大到15.2%。CJRC数据集的统计数据以及与其他数据集的对比如下:
表2 CJRC的数据统计
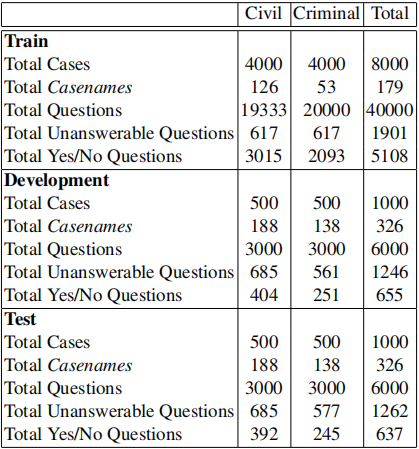
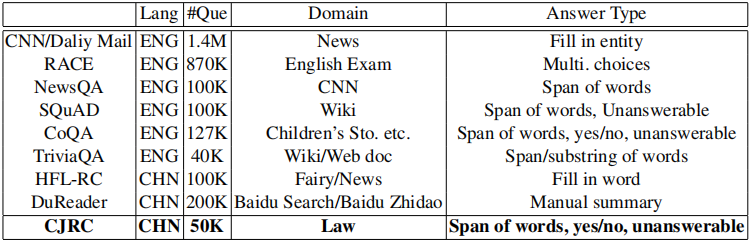
表3 CJRC与其他数据集的对比
实验对比
我们采用BERT、BiDAF作为基线系统,采用与CoQA一致的F1宏平均(Macro-average F1)作为评价指标,对比了基线系统与人类指标,以及对比了基线系统在数据集不同数据分布下的结果:
表4 BERT、BiDAF与人类指标在数据集不同数据分布下的对比
同时,参赛系统的成绩分布如图2,其中第一名参赛系统比人类指标低9.3%,比BERT基线系统高4.6%。
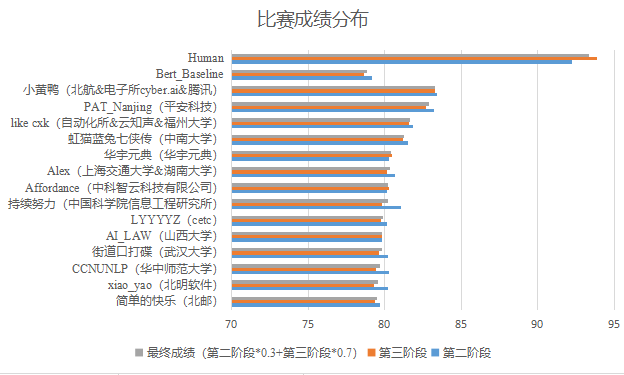
图2 参赛系统、人类指标、基线系统的成绩分布
总结
本文我们提出了首个中文法律阅读理解数据集,该数据集具有以下特性:
- 涉及范围广,包括188种民事案由以及138种刑事罪名;
- 涉及问题种类丰富,包括片段型、是否类以及拒答类的问题;
- 具有较广阔的应用前景,比如要素抽取、问答系统等。
通过对比人类指标与基线系统以及参赛系统,说明在该数据集上仍存在较大的提升空间。我们希望通过该数据集能够促进法律领域相关任务的技术研究,也欢迎广大研究者在该数据集上做进一步研究。
延伸阅读
- CoNLL 2019 | TripleNet对话回复选择
- EMNLP 2019 | 法小飞:中文法律智能助手
- EMNLP 2019 | 基于篇章片段抽取的中文阅读理解数据集
- EMNLP 2019 | 跨语言机器阅读理解
- 哈工大讯飞联合实验室三篇论文被EMNLP-IJCNLP 2019录用
