实验室刷新国际大赛SQuAD2.0新纪录
11月16日,在新揭晓的SQuAD2.0排行榜上,哈工大讯飞联合实验室团队(HFL)从谷歌(Google AI)、阿里达摩院(Alibaba DAMO)、微软亚洲研究院(Microsoft Research Asia)等业界翘楚中脱颖而出,获得排行榜第一 。
从1.1到2.0:测试高度再升级
SQuAD(Stanford Question Answering Dataset)是认知智能行业内公认的机器阅读理解领域的顶级水平测试,通过吸收来自维基百科的大量数据,SQuAD构建了一个包含十多万问题的大规模机器阅读理解数据集,这使得在这个数据集上训练大规模复杂算法成为可能。
本次参测的SQuAD2.0相比此前的SQuAD1.1,在基于篇章片段抽取的阅读理解任务的基础上进一步提高了解答难度,对机器阅读理解模型提出了新的挑战。其难度主要在于在新版本数据集中加入了“不可回答的问题”,即参赛团队所提交的机器阅读理解模型需要通过阅读篇章和问题,判断所提出的问题是否能够通过篇章内容进行回答,如果可以回答,则根据篇章中的内容作出答案;如果不可回答,则需要对题目进行拒答。
认知智能新突破:科大讯飞再夺第一
2018年对于以机器阅读理解为核心的认知智能来说是不平凡的一年,从上半年哈工大讯飞联合实验室在语义评测SemEval-2018和CGEG中相继夺冠到下半年Google提出的BERT模型在各类自然语言理解测试中频频刷榜,中西方智慧在交流中不断助力全球认知智能领域研究迈上新台阶。
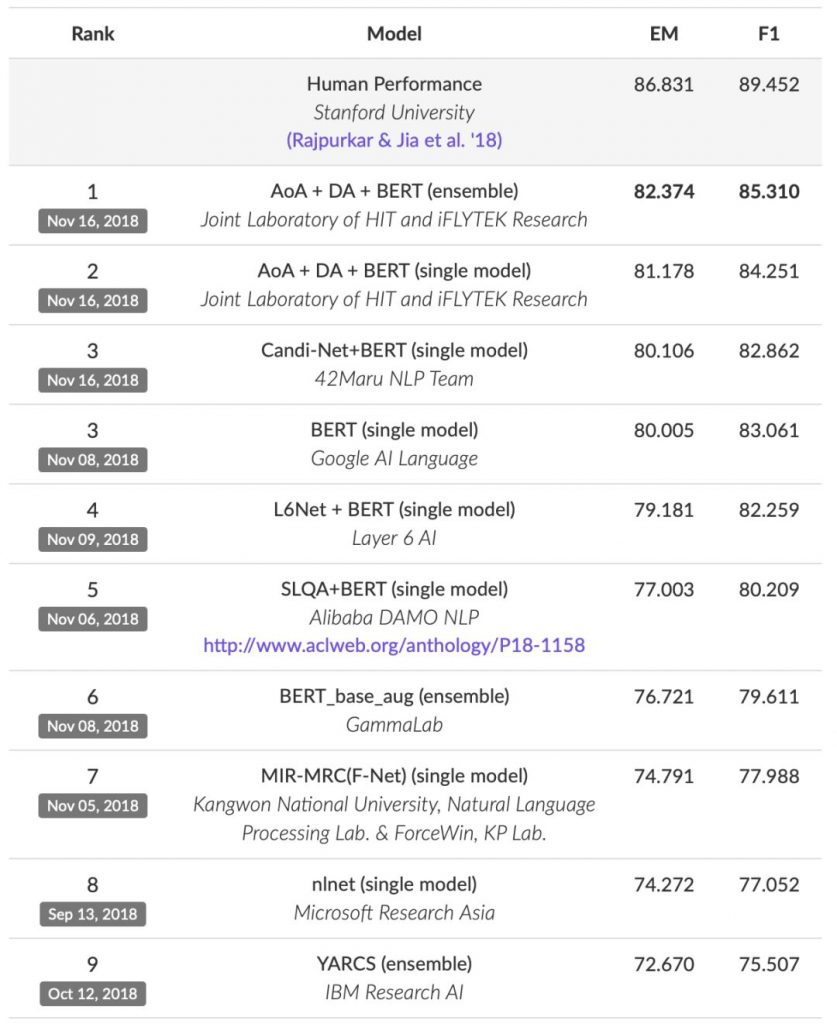
作为全球范围内较早启动机器阅读理解技术研究的团队,哈工大讯飞联合实验室阅读理解团队(HFL-RC)此前已多次荣登SQuAD榜首。在本次提交的系统中,哈工大讯飞联合实验室在吸收业界最新前沿技术的同时又加入了已有的原创核心技术,不仅将评测中的两项指标进一步提升到新的高度,还在各自单模型系统(Single Model)的对比中,以显著优势赢得胜利。

从具体指标来看,哈工大讯飞联合实验室所提交的模型在EM指标(Exact Match,精准匹配率,预测答案和真实答案完全匹配,即机器给出的答案需要和人一样才算正确)上达到82.374,F1指标(F1-score,模糊匹配率,即将答案短语切成词,与人类答案共同计算回归率和准确性,如果机器模型的答案并没有完全匹配也可以得分,用以表示评测模型的整体性能)上达到85.310,进一步缩小了机器与人类认知水平在该数据集上的效果差距(EM:86.831,F1:89.452)。