再夺桂冠!实验室荣登HotpotQA阅读理解评测榜首
2020年5月21日,哈工大讯飞联合实验室(Joint Laboratory of HIT and iFLYTEK Research, HFL)与河北省讯飞人工智能研究院联合团队再次取得技术突破,在由卡内基梅隆大学(CMU)、斯坦福大学和蒙特利尔大学联合发起的多步推理阅读理解评测HotpotQA全维基赛道中荣登榜首,其中综合模糊准确率(Joint F1)指标达到66.22、综合精准准确率(Joint EM)指标达到40.36,大幅刷新评测指标。这是继2019年10月首次在HotpotQA评测干扰项赛道夺冠后,再次夺得该项评测的桂冠。
多步推理阅读理解评测HotpotQA自2018年发布以来吸引了大量知名高校和研究机构参与,其中全维基赛道上更是高手云集,其中包括微软、Salesforce、华盛顿大学、马里兰大学、卡耐基梅隆大学、清华大学、北京大学、谷歌、斯坦福大学、阿里巴巴达摩院等。
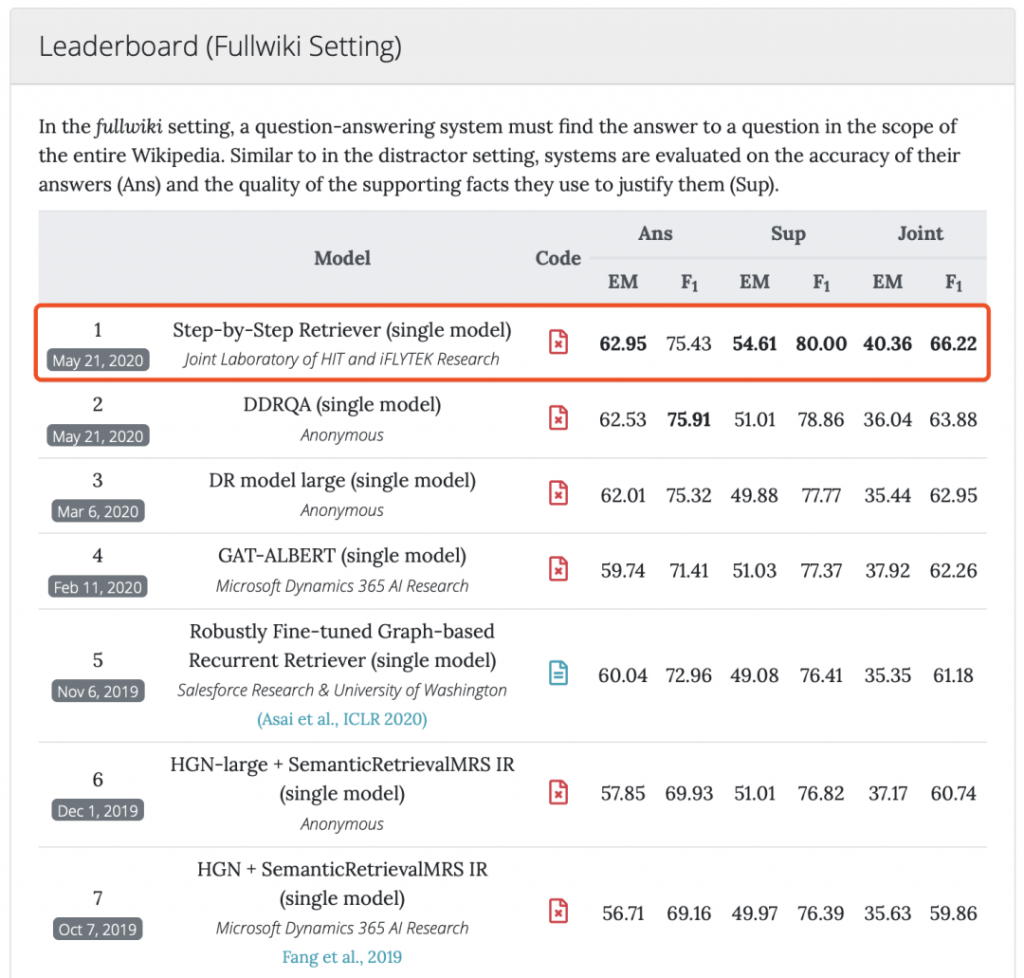
本次提交的Step-by-Step Retriever模型根据多步推理形式文档检索的主要挑战进行了特别设计,主要包括以下特点:
- 模型采用了与C2F Reader(即去年提交到干扰项赛道的模型)相同的pipeline结构,实现了篇章的初筛到精筛的过程,并且通过多步推理阅读理解模型预测出最终的佐证证据和答案。
- 受神经图灵机(Neural Turing Machine)的启发,我们设计了一种可读写的外部记忆体来存储之前检索到的篇章,并对篇章之间的联系进行深度建模。
- 通过门机制(Gate Mechanism)来控制外部记忆体的读写行为,消除了大量无关篇章可能造成的检索干扰。
相比于传统的文档检索模型仅仅匹配与问题具有最多共现关键词的文档,拥有多步推理能力的文档检索模型能够进一步挖掘潜在的相关文档,对于这一领域的研究在未来的应用落地具有重要价值。