实验室荣获国际语义评测SemEval 2022两项冠军,多语种语言理解再上新台阶
近日,第十六届国际语义评测(The 16th International Workshop on Semantic Evaluation, SemEval 2022)大赛落下帷幕,哈工大讯飞联合实验室以显著领先优势在“多语种新闻相似度评测任务”(Task 8)、“多语种惯用语识别任务”(Task 2: Subtask A one-shot)子赛道中夺得冠军,在多语种语言理解领域持续进阶。
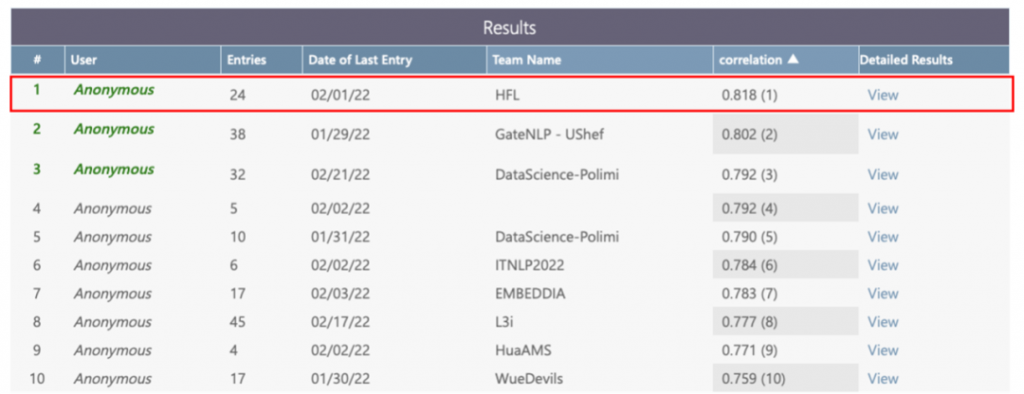
SemEval 2022评测由国际计算语言学协会(Association for Computational Linguistics, ACL)旗下SIGLEX主办,迄今已举办16届,参赛者覆盖国内、外一流高校及知名企业,包括达特茅斯学院、谢菲尔德大学、华为、阿里达摩院等,代表着最前沿国际技术和水平。
新闻相似度评价:目光如炬
Task 8是多语种新闻相似度评价任务。任务中给出来自多种语言的新闻篇章对,参赛队伍需要利用模型判定每一对新闻篇章是否描述了同一个事件,并以1至4分的范围为两篇新闻的相似度打分。任务共计覆盖10种语言,包括阿拉伯语、德语、英语、西班牙语、法语、意大利语、波兰语、俄语、土耳其语和中文。与普通的文章相似度任务相比,该评测任务强调考察模型的跨语言理解能力,并要求模型把握文章中描述的具体事件,而不仅是写作风格。下面用一则示例为大家解读。

SemEval 2022 Task 8 任务数据样例,包含7个维度的相似度打分,分数越低越相似
图中列举了两篇相似度极高的新闻稿件,参赛队伍必须将文中相似的主要元素剥离出来并逐一分析,比如地理信息、叙事技巧、实体、语气、时间及风格,最终得出两篇文章的相似度与差异化。 与普通的文章相比,该项比赛更强调跨语言理解能力,除了写作风格和叙述方式外,还需要把握文章中描述的具体事件。通俗来说,该项技术可以甄别外网的一些新闻报道是否存在偏差与曲解,从而有效预防虚假信息、不良信息的传播。
惯用语检测:熟能生巧
Task 2 Subtask A是惯用语检测。通俗来说,无论你是哪国人,在日常表达中都有一类短语的固定用法,并且该固定用法通常与短语的字面语义不同,我们会将这些短语称为“惯用语”。想要理解包含惯用语的句子,首先需要判断句子中的多字短语是否为惯用语,比如“说曹操,曹操到。”句中的曹操是否真实存在。 该任务的形式便是给定一个目标语句,包括其上下文和多字短语,继而判断该语句中的多字短语用法究竟是惯用语还是字面意思。该任务为多语言任务,包含英语、葡萄牙语、加利西亚语三种语言。其中加利西亚语没有在训练集中出现过,因此科大讯飞代表队需要在不同语言之间进行迁移学习。下面用一则示例为大家解读。

如例所示,Literal表示字面意思,第一句话可翻译为:当你从网中抓一条大鱼时,最好撑住它的腰。Idiomatic表示惯用语,所以第二句话中再次出现了大鱼一词,但却不是简单的字面意思,而是“大人物”。 所以该任务要求参赛队伍区分不同句子中同一个词的不同语义,这需要强大的分析及跨语言理解能力。有了该项技术,在日常写作和翻译工作中,即可有效鉴别惯用语的表达用意,极大提高内容准确率。
夺冠系统
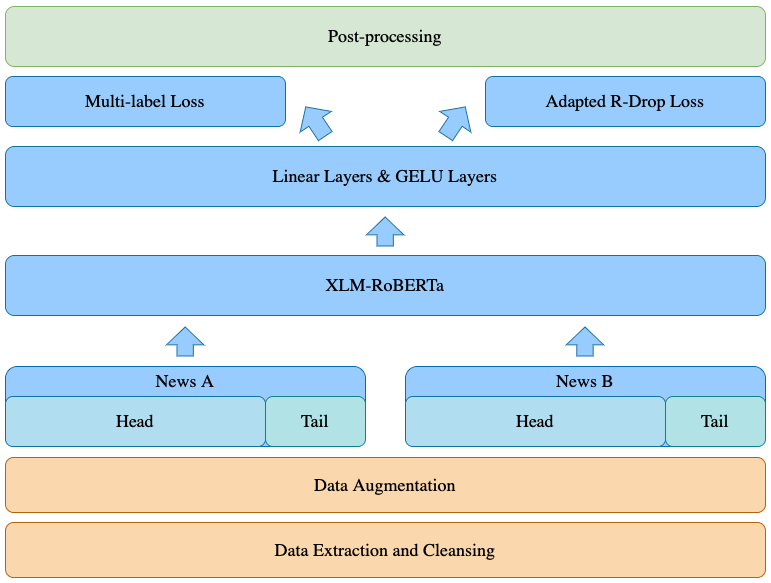
夺冠系统选用XLM-RoBERTa作为基模型,并设计了针对该数据集的多任务联合训练目标及任务适配的R-Drop损失学习。后处理方面使用了打分裁剪,对系统结果进行进一步优化。此外,还尝试了对模型加大增宽、双塔交互等训练方式。数据方面,由于测试集相比训练集多出3种语言、7种跨语言组合,因此对未覆盖的语种进行了数据增强,并基于新闻篇章的结构特性,进行了头尾不同比例的信息融合。更多信息请参阅系统描述文章:https://arxiv.org/abs/2204.04844
除了本次SemEval 2022评测之外,哈工大讯飞联合实验室在多语种技术方面取得了多项突破。在去年,哈工大讯飞联合实验室在多语种理解评测XTREME任务中夺得冠军,并发布了首个面向少数民族语言的预训练模型CINO。在本次评测任务中,团队借鉴了XTREME评测任务的技术与经验,从而使模型性能获得了显著提升。