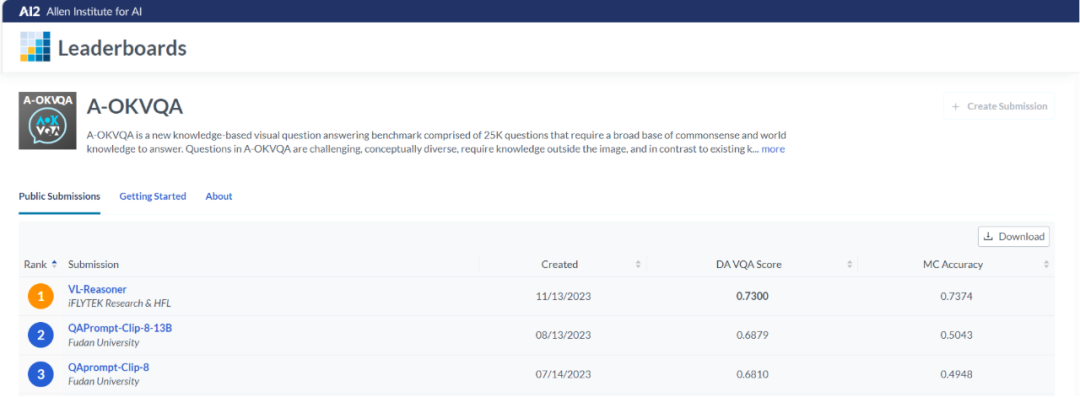
基于外部知识的多模态问答评测A-OKVQA放榜,认知智能全国重点实验室夺冠
先来看一道机器的考试题:图中的水果,哪种在剥皮时如果离你的脸太近可能会伤到你的眼睛?

答案是橙子,因为切橙子的时候会有酸性液体溅出,如果脸靠得太近,有可能会溅射到眼睛里。
类似的考试题,来源于由知名AI研究机构AI2(艾伦人工智能研究院)所举办的基于外部知识的多模态问答评测A-OKVQA(the Augmented successor of Outside Knowledge Visual Question Answering),旨在全面考察模型的跨模态结合外部知识进行推理问答的能力。近日,认知智能全国重点实验室团队在该评测中收获冠军,在DA VQA Score评测指标上显著超越其他参与团队。

难度升级:跨模态、基于外部知识、生成式回答
A-OKVQA评测自2022年举办以来吸引了众多知名高校、研究机构和企业参加,例如北京大学、复旦大学、罗切斯特大学、华盛顿大学、AI2、微软等团队。作为基于外部知识的视觉问答评测,A-OKVQA评测的任务形式是让机器理解一个图片,并回答问题。但与其他大多数VQA评测任务不同,A-OKVQA主要考察模型结合外部知识和图片内容回答问题的能力。
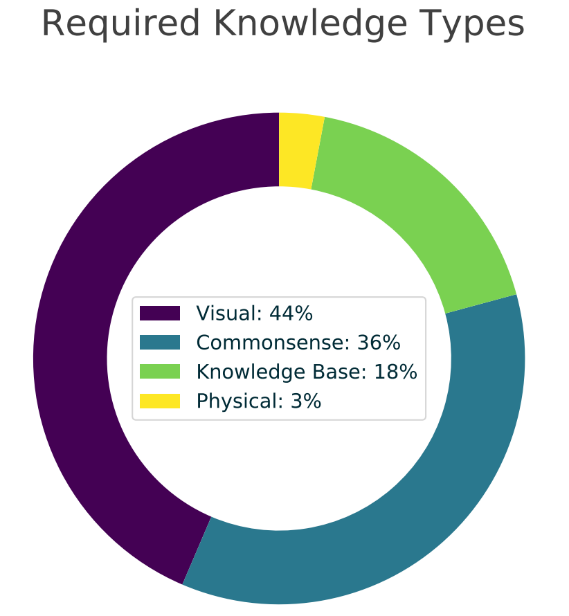
这些问题一般不能通过简单地查询知识库或图片信息来回答,而是需要对图像中描述的场景进行常识推理,回答这些问题需要的知识包括常识性知识、视觉知识、知识库知识、物理知识。例如开头所举例的题目,就需要了解“橙子切开会溅出酸性液体”的常识,并对液体溅入眼睛后可能会带来伤害进行推理。
A-OKVQA 评测中的每个问题都设置了选择题选项和10个自由形式答案,考核指标则有两种:直接答案 (Direct Answer, DA) 评估和选择题 (Multi Choice, MC)评估。直接答案评估中,模型需要生成文本答案,使用DA VQA Score评估,根据预测答案与10个标注答案匹配的数量计分(最多按3个计分);在选择题评估中,模型从给出的选项中选择一个答案,计算准确率作为评估指标。再来看一个评测题目例子:
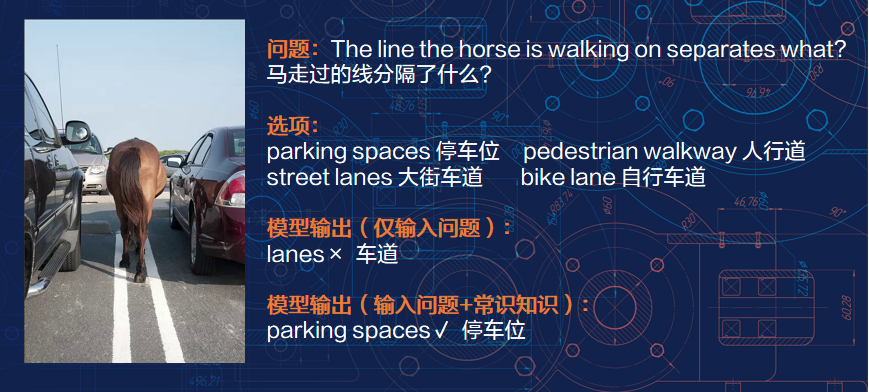
A-OKVQA评测的难点可见一斑:
- 首先需要理解问题,找到图片中与问题相关的实体、问题与图片之间的联系以及对应的逻辑关系,即需要准确定位与问题和图片相关的外部知识。例如,上面例子中,模型需要在图片里识别到马和周围的车辆等物体;
- 其次,根据车辆的排列、背景环境情况判断出这是在停车场而非马路,所以马脚下的线应该是停车位之间的分割线;
- 最后,在准确定位外部知识和问题图片中实体逻辑关系后,需要根据图片问题内容生成对应答案。
夺冠系统VL-Reasoner:超大语言模型与视觉大模型轻量级结合
此次认知智能全国重点实验室实现夺冠的秘诀,在于团队创新提出的VL-Reasoner模型,属于Reasoner系列模型之一。Reasoner系列模型是认知智能全国重点实验室专门用于处理推理型阅读理解任务的系列模型,此前也在多个机器阅读理解国际权威赛事中收获第一。今年,Reasoner系列模型再度升级,研发了针对多模态的问答推理模型,在此次评测中取得了优异成绩。
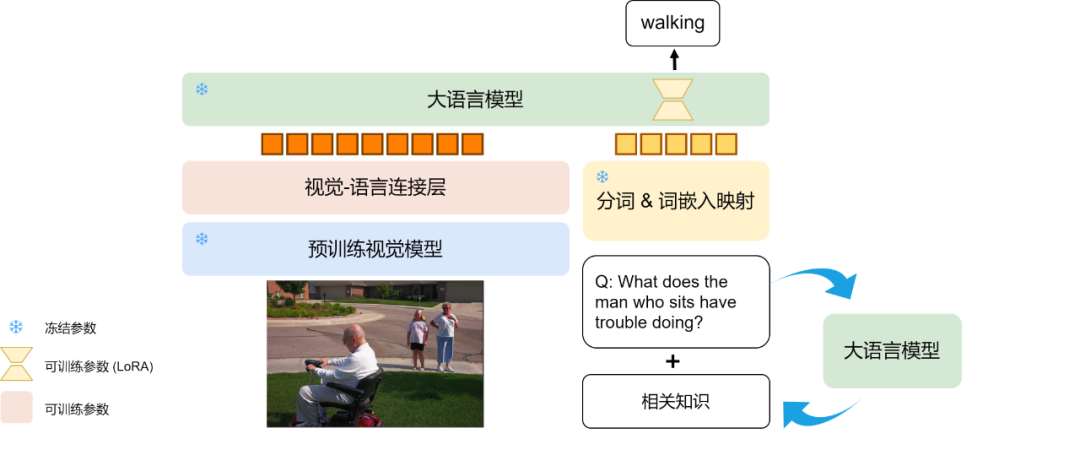
VL-Reasoner模型主要有两大亮点:
- 借助问题上下文信息指导大模型,引导其生成与问题和图片相关的知识,从而提高答案的准确性。
- 大语言模型高效参数精调(LoRA):对比只训练视觉–语言连接层,对大模型采用LoRA的方式进行训练,提高模型在下游任务上的泛化能力和性能稳定性,有助于模型更好地理解和利用不同模态数据之间的关联。
该模型使用视觉-语言连接层,将预训练过视觉模型和大语言模型轻量级结合,实现了跨模态推理问答。

利用大语言模型生成能力,VL-Reasoner模型能更好应对A-OKVQA评测中的各种挑战,最终在评测中拿下第一。
大模型与视觉模型“跨模态协同并进”,应用大有可为
VL-Reasoner模型系统同时结合了大语言模型和视觉模型的能力,从而提升了在视觉推理问答任务上的效果。对于讯飞星火认知大模型来说VL-Reasoner模型在多模态能力上具有重要的借鉴价值意义:通用底座大模型不仅可以独立地完成各种自然语言处理任务,还可以通过与视觉模型结合,在跨模态推理问答任务上发挥重要作用,在实际应用中展现出更好的能力。
此前,认知智能国家重点实验室已多次在国际机器阅读理解评测赛事中取得优异成绩。Reasoner系列模型“队伍”的壮大与持续收获的好成绩,也是实验室在认知智能与大模型相关技术上不断创新突破的表现。未来,实验室将继续瞄准让“机器能理解会思考”的目标持续攀登,积极推动核心源头技术的进步与应用落地实践。