第五届中文语法错误自动诊断大赛中夺冠
第五届中文语法错误自动诊断大赛(Chinese Grammatical Error Diagnosis,简称 CGED)2018年7月在澳大利亚墨尔本举办。本届CGED评测的参赛者可谓高手如云,团队包括中国社科院、阿里巴巴、北京大学、哈工大讯飞联合实验室(下文简称HFL)等,最终由HFL竞得冠军。
外国人写的中文错句做考题 新增“语病修正”项获最高分
写完一篇作文,语文老师批改时从里面选出多余的词、缺少的词、使用不当的表述、以及语序不通的表述,然后一一改正过来。这样的场景,现在已经成为一场世界性的比赛——第五届中文语法错误自动诊断大赛(简称CGED)(比赛官网:http://www.cged.science)。今年第五届的评测大会于上周四(2018年7月19日)在澳大利亚墨尔本举行,这场比赛最终由哈工大讯飞联合实验室摘得桂冠。
比赛方式是,主办方挑选了一些外国人写作的中文句子片段,让参赛者通过人工智能算法技术对其中的语法语义错误进行识别并进行系统性能评估。
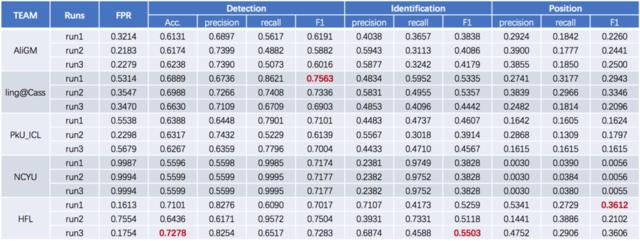
今年共13个团队参加CGED评测,所选“考题”有四种错误类型,具体包括多词、缺词、用词不当和语序不当。
比赛从四个维度对参赛者的能力进行评估:语病识别(即:识别句子是否有错误)、语病分类(识别具体的错误类型)、语病定位(识别错误的位置和类型)、语病修正(对于缺词和错词,提供修正的建议)。一共有13个团队参加了这项比赛。
在这四项成绩中,哈工大讯飞联合实验室获得了后三项的第一名、以及第一项的第二名,总体排名第一,首次参赛便摘得冠军。
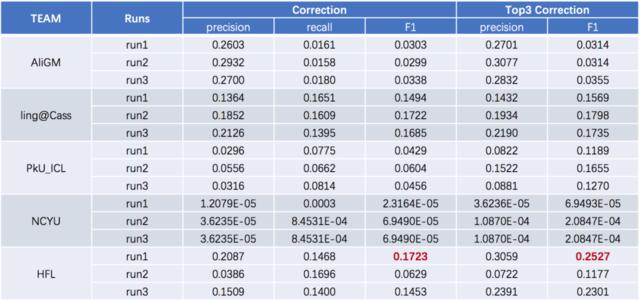
值得一提的是,去年的比赛只有三项成绩,第四项“语病修正”是今年才增加的比赛分项。和去年相比,除了“指出问题”,还提供“解决答案”,其难度更上一级。在“语病修正”的任务中,在“第一候选”或“前三候选”项,HFL分别获得0.1723分和0.2527分,以绝对领先的成绩排第一名。
纠错语法AI冠军如何诞生?通过神经网络序列标注模型生成
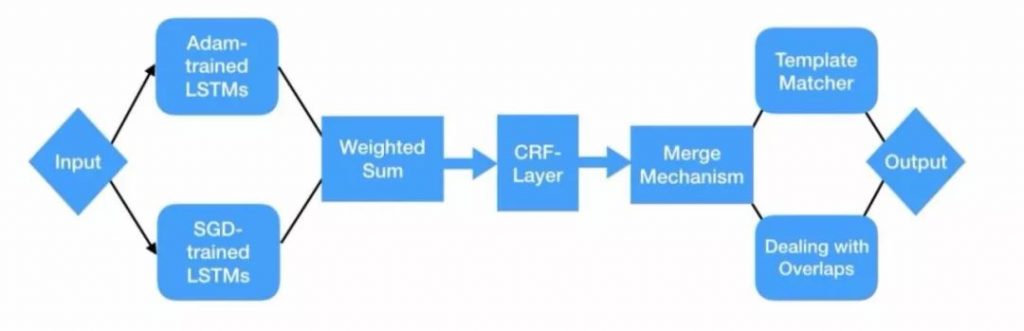
此次夺冠,有赖于对神经网络序列标注模型BiLSTM-CRF进行改进,包括底层的整个模型、单模型内部的融合、模型外的融合三大板块。具体而言——
第一,将词向量、统计、先验的语法知识相融合,如汉语语言习惯用法等统计特征,比如“静静的顿河”和“静静地等待”中结构助词“的”和“地”的使用会根据上下文的词性而决定;
第二,采用模型内部融合的技术,将多个BiLSTM单模型的输出加权融合,再经过CRF计算最终结果;
第三,采用了模型选取、模型排序等外部融合方法,发挥了不同模型的优势。
中文比英文语病纠错难度大得多 语病纠错应用前景广泛
需要说明的是,在语病纠错领域,中文比英文难度大得多。这主要由两个原因决定的:第一,英语语法规范,有严格的主谓宾;第二,英文积累的语料丰富,剑桥大学已经积累了上千万个句子。
相较之下,中文语法灵活,语病检测的技术难度高得多,而且目前参加评测的语料库只有3万多个句子,语料量亟待扩充。
所以,目前英语语法纠错已经有成熟的应用,而中文的语法纠错还处于不断积累和探索的阶段。从现在的评测结果来看,目前的技术指标还比较低,离实际应用尚需时日。
值得期待的是,无论是学习外语,还是文稿的错字校对,这次参赛获奖的语病检测和修正技术未来都将有广泛的应用前景。