对话型阅读理解挑战赛QuAC中夺冠
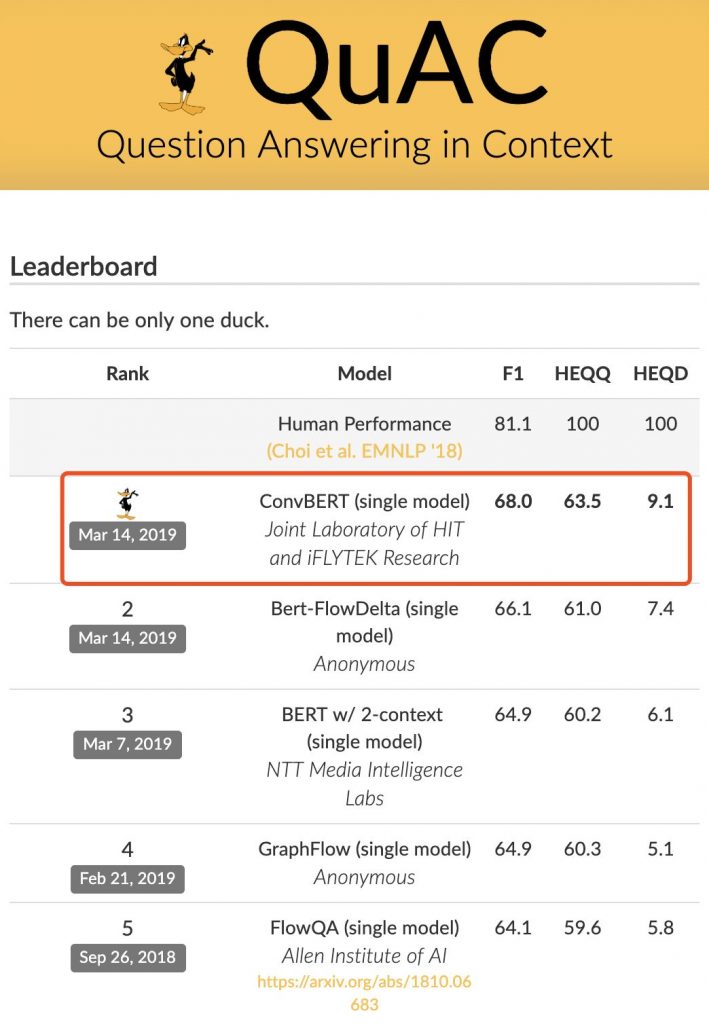
2019年3月14日,哈工大讯飞联合实验室与河北省讯飞人工智能研究院联合团队在由艾伦人工智能研究院(AI2)、斯坦福大学和华盛顿大学联合发起的对话型阅读理解评测QuAC中凭借所研发的ConvBERT模型荣获冠军,全面刷新所有评测指标,其中F1(模糊准确率)达到68.0,进一步拉近了机器与人类在该任务上的水平差距。
对话型阅读理解评测QuAC与权威的阅读理解评测SQuAD及同期的对话型阅读理解评测CoQA均有所不同。首先,与SQuAD评测相比,QuAC将单轮的问答形式拓展成多轮的对话。
与另一对话型阅读理解评测CoQA不同的是QuAC中回答者(Teacher)一方面需要从篇章中抽取出更为复杂的篇章片段作为答案,同时还需要判断对话行为(Dialogue Act),包含肯定和否定(Yes/No)、是否有答案(No Answer)和是否继续上一个话题(Follow-Up),所以具有更浓的对话色彩。
除此之外,QuAC数据中的篇章以及答案相比SQuAD和CoQA要长,使得篇章理解和答案输出的难度大大增加。在评测标准上,QuAC评测不仅包含答案的模糊匹配率F1,而且更加强化了机器答案与人类结果在问题和文档两个粒度上的效果对比,其中HEQQ是机器答案达到或超过人类的问题比例,HEQD是同一个篇章内所有问题上机器都达到或超过人类的篇章比例。从这两个指标可以更加直观看出,ConvBERT模型进一步拉近了机器与人类在该任务的水平差距。同时,ConvBERT直接应用在另一对话型阅读理解评测CoQA上也取得了良好的效果。
本次提交的ConvBERT(Conversational BERT)模型融合了业界领先的语义表征模型BERT,并在此基础上针对对话型阅读理解任务进行了优化设计,其中主要包括如下几个特点:
1、在传统的阅读理解模型的基础上,针对多轮对话的特点,ConvBERT不仅对篇章和当前的问题进行建模,同时充分考虑历史的问答信息对当前问题的影响,使历史对话信息参与到当前答案预测,从而得到更加精准的答案;
2、在语义表征模型BERT的基础上,进一步使用了自注意力(Self-Attention)结构,使得模型在预测时能够更加关注到重要的篇章片段以及历史对话;
3、针对QuAC任务篇章较长的特点,ConvBERT能够针对切片后篇章进行分别解答,并最终通过答案融合模块将多个篇章切片得到的答案进行综合,从而进一步提高答案的准确率;
4、通过生成伪训练数据的方法,进一步扩充训练语料。